“John, tem um sistema aqui que ninguém quer tocar. Se mexer, cai.”. Já ouvi isso mais vezes do que troquei pastilha de freio na minha moto. E adivinha? Era sempre o sistema por onde o dinheiro da empresa passava: pedido que fecha, boleto que compensa, carga que sai.
Todo time tem o “não mexe que quebra”. Feioso, meio remendado, escrito por arqueólogos apressados. E é justamente ali que quem sabe o que está fazendo vira peça rara. Peça rara escolhe onde trabalha e quanto quer ganhar.
O que é, de verdade, “legado”
Nada místico. É software crítico pro negócio que ficou caro de evoluir:
Antigo ou sem testes.
Dependências defasadas e documentação rala.
Conhecimento na cabeça de duas pessoas.
Às vezes com tech moderna… mal acoplada.
Resumo: se parar, dói no caixa; se mexer, dá medo. E medo sem processo vira bloqueio.
Por que legado acelera sua senioridade (na prática)
Quer ganhar “anos de experiência” em meses é só mexer em código que não é seu, pode ser desconfortável no começo, mas um acelerador absurdo depois:
Leitura de código de terceiros: Você decifra intenções e padrões, enxerga com os olhos de quem fez.
Escavação de software: Bug fantasma? Você investiga os logs, reconstrói o fluxo e acha a dependência escondida.
Frieza em produção: Incidente vira laboratório: logs, tracing, métricas, feature flags, rollback e hotfix sem pânico.
Refatoração pé‑no‑chão: Em vez de “reescrever tudo”, você melhora aos poucos e entrega valor rápido.
Cabeça de negócio: Legado te força a entender domínio (fiscal, pagamento, logística). Você sai de dev de código para dev que resolve o problema certo.
Comunicação de adulto: Negociar escopo, explicar risco e escrever o documento que salva plantão.
Opinião forte: ler código de outras pessoas é o maior multiplicador de carreira que existe.
Empregabilidade: pouca gente quer… todo mundo precisa
Toda empresa vive o dilema: manter o presente (que fatura) e construir o futuro (modernizar). Falta gente que faça a ponte. Quem se posiciona como especialista em estabilização + modernização gradual vira premium:
Resolve dor crônica (incidentes repetidos, deploy com medo, integrações frágeis).
Reduz risco (menos queda em fechamento, menos chargeback, menos multa).
Acelera time‑to‑value (pequenas correções que destravam resultado).
Espalha conhecimento (runbooks, docs, ADRs) e reduz dependência de heróis.
Tradução pro gestor: você protege receita. Quem protege a receita é contratado primeiro.
Dinheiro na mesa: por que essa habilidade puxa seu salário
Salário sobe com impacto visível + escassez. Em legado dá para mostrar, com números:
Queda de P0/P1 e MTTR derrubado (ex.: 2h para 25 min).
Menos timeout/rollback.
+X% na taxa de aprovação de pagamento ao corrigir idempotência/timeouts.
Tela crítica X% mais rápida.
Poucos topam. Quem topa e entrega vira referência, e referência negocia melhor.
Frase pra negociação: “Eu reduzo risco e protejo faturamento. Aqui estão as métricas.”
Muda a conversa de “código por hora” para valor de negócio.
Plano tático: transforme legado em vantagem (6 passos)
Mapeie o terreno: Diagrama simples do sistema, quais os fluxos críticos, integrações e os pontos frágeis.
Ataque alto ROI: Query lenta, endpoint instável, job sem idempotência. Meça o antes e o depois.
Crie anticorpos: Testes onde dói, logs bem estruturados, métricas, tracing, alertas com SLOs.
Refatore usando Strangler Fig: Encapsule, estabilize as APIs, extraia fatias com compatibilidade.
Prenda conhecimento: Runbooks, ADRs e guias de troubleshooting.
Conte a evolução: Changelog de melhorias. Munição para performance review e entrevista.
Mini‑exemplo (realista e genérico)
Antes: checkout com 3% de erro intermitente; MTTR de 2h; Deploy 1x por semana com rollback frequente.
Ação: Idempotência nos webhooks; Retries com backoff; Logs estruturados; Testes de contrato com adquirente.
Depois: Erro <0,5%; MTTR de 25min; Deploy 3x por semana sem rollback; Aprovação de +2,8%.
Como contar essa história no currículo/entrevista
Resumo de perfil: “Especialista em estabilização e modernização de sistemas críticos de alto volume.”
Bullets de impacto:
Reduzi MTTR de 2h para 25min com observabilidade e runbooks.
+3,1% na taxa de autorização ao corrigir idempotência/timeouts com adquirentes.
Deploys semanais sem rollback ao implementar testes de contrato.
Strangler no módulo X, removendo 40k linhas de código morto sem downtime.
“Legado atrasa carreira.” Acelera. Você aprende o que quebra, e como não quebrar.
“Só reescrevendo resolve.” Quase nunca. Modernização incremental entrega cedo e com menos risco.
“Ninguém valoriza.” Quem carrega pager sabe.
Trilha de estudo para virar referência
Leitura de código (tours de arquitetura), observabilidade (logs estruturados, OpenTelemetry, métricas de negócio), banco (índices, plano de execução, migração segura), confiabilidade (retry com backoff, circuit breaker, filas, idempotência, carga), modernização (anti‑corruption layer, Strangler, testes de contrato, evolução de schema).
Mantra: Eu não só escrevo código, eu mantenho o negócio de pé enquanto o futuro chega.
FAQ rápido
“Vou virar síndico do legado?” Não se você documentar, treinar time e automatizar o que quebra.
“Qual stack importa?” A que sua empresa usa agora? Conceitos de confiabilidade e domínio valem em qualquer stack.
“Quanto tempo ficar?” O suficiente para medir impacto e espalhar conhecimento. Depois, escale ou gire pro próximo gargalo.
Quem nunca se empolgou com uma nova tecnologia, um padrão arquitetural interessante ou um case de sucesso de uma big tech e pensou: “por que não aplicar isso aqui também?” A verdade é que esse impulso, embora nasça de uma boa intenção, pode nos levar direto para a armadilha do over engineering, um problema mais comum do que parece.
Neste artigo, quero compartilhar reflexões sobre o que é over engineering, como identificá-lo, por que caímos nessa armadilha e, principalmente, como evitamos esse excesso aqui no Asaas, sem abrir mão da qualidade do que construímos.
O que é over engineering?
Over engineering é quando criamos uma solução mais complexa do que o necessário para resolver o problema que temos no momento.
É como instalar um sistema automatizado de irrigação com sensores, temporizadores e integração com a previsão do tempo só para cuidar de um vasinho de planta que poderia ser regado com um copo d’água.
A metáfora pode parecer exagerada, mas traduz bem a essência do problema: estamos colocando energia e recursos demais para resolver algo que, na prática, poderia ser simples.
O grande perigo está no impacto desse excesso: atrasos em entregas, aumento da complexidade do código, dificuldade de manutenção, curva de aprendizado maior e, muitas vezes, pouco ou nenhum valor adicional para o cliente final. E o pior: tudo isso parte, na maioria das vezes, de boas intenções.
Como identificar que estamos caindo nessa armadilha?
Existem alguns sinais que nos ajudam a perceber quando estamos indo além do necessário:
Excesso de abstração para pouca funcionalidade: Quando criamos interfaces, serviços e camadas demais para algo que, no fundo, faz pouca coisa.
Código difícil de entender e explicar:Se você precisa de dez minutos para explicar uma função, talvez ela esteja mais complexa do que deveria.
Uso de padrões e ferramentas “por padrão”, sem uma razão real: Muitas vezes, adotamos estruturas porque estão na moda ou porque lemos sobre elas em artigos técnicos, mas esquecemos de nos perguntar se realmente precisamos daquilo.
Pouco valor entregue depois de muito esforço: O retrato clássico de um time que trabalhou muito, mas entregou pouco.
Quando você precisa abrir mais de 5 diagramas para explicar sua estrutura.
Decisões baseadas em achismos, e não em dados ou necessidades reais.
Já presenciei situações em que uma simples integração com outro sistema foi pensada como uma arquitetura robusta de orquestração de eventos, com filas, retries e fallback, tudo isso antes mesmo de sabermos se o sistema parceiro era estável ou se o volume de uso justificava tanta preparação. Quando isso acontece, o risco de criarmos algo desnecessariamente complicado é enorme.
Por que isso acontece?
Over engineering geralmente nasce de uma combinação de fatores. Alguns deles:
Insegurança técnica: O medo de errar faz com que a gente tente se proteger com soluções “à prova de tudo”.
Desejo de mostrar domínio técnico: Às vezes, queremos mostrar que sabemos muito e, sem perceber, deixamos de lado a simplicidade.
Influência de grandes empresas: Consumimos muitos conteúdos de empresas como Google, Amazon, Netflix, que lidam com desafios de escala imensos. Aplicar as mesmas soluções fora desse contexto pode ser um erro.
Liberdade excessiva: A ausência de padrões ou direcionamento pode fazer com que cada desenvolvedor tome decisões por conta própria, levando a soluções inconsistentes e, muitas vezes, superdimensionadas.
FOMO (Fear of Missing Out): A ansiedade de estar por dentro de tudo o que é novo pode nos levar a adotar tecnologias ou práticas antes mesmo de saber se são úteis para o nosso caso.
Como equilibrar robustez e simplicidade?
Aqui no Asaas, temos um esforço constante para buscar esse equilíbrio. Como liderança técnica, procuramos estimular o time com perguntas provocativas, como:
“Isso resolve o problema de hoje ou o que talvez surja mês que vem?”
“Qual volume (requests, dados, usuários) atual?”
“Testamos uma versão mais simples antes de chegar nessa proposta?”
Valorizamos soluções simples e bem feitas tanto quanto aquelas mais elegantes e complexas. Buscamos criar um ambiente em que o “simples que funciona“ tem espaço, é reconhecido e celebrado. Isso ajuda a frear o impulso de complicar sem necessidade.
O que fazemos para evitar o over engineering
No dia a dia, algumas práticas têm nos ajudado bastante:
Revisões de PR com foco em clareza e propósito: Mais do que encontrar bugs, usamos os PRs para avaliar se a solução faz sentido, segue nossos padrões, é fácil de manter e resolve o problema real.
Propostas técnicas antes do desenvolvimento: Isso nos permite alinhar expectativas e evitar surpresas no meio do caminho.
Construção de MVPs reais, ou seja, não só no produto, mas também na arquitetura:Entregar uma primeira versão enxuta da arquitetura permite validar hipóteses com menor custo. Isso sem deixar de lado a qualidade da entrega.
Documentação técnica com princípios e padrões claros (aqui no Asaas conhecido como o “Livro de Elite”).
Quando a complexidade é necessária e como reconhecê-la
Nem toda complexidade é ruim. Às vezes, ela é necessária, e fugir dela seria até irresponsável. Mas há uma diferença importante entre complexidade necessária e over engineering.
A complexidade necessária vem depois da evidência. Ela aparece quando testamos uma abordagem simples e ela não foi suficiente. Quando sabemos, com dados, que falhas terão impacto alto demais. Quando o sistema exige algo mais robusto.
Já o over engineering é o oposto. A complexidade aparece antes da evidência, baseada em suposições, medos ou vaidade técnica.
Conselhos para devs que querem fugir dessa cilada
Se você está começando na área, alguns conselhos podem ajudar:
Antes de sair codando, pergunte: “qual a forma mais simples de resolver isso?
Valide sua ideia com alguém mais experiente ou pergunte-se: “estou resolvendo um problema real ou um cenário hipotético?”
Pratique o YAGNI (You Aren’t Gonna Need It): não implemente algo que talvez só vá precisar no futuro.
E lembre-se: soluções simples bem executadas são quase sempre melhores do que ideias geniais mal encaixadas.
Como se manter no foco
Costumo repetir algumas frases para ajudar a manter os pés no chão:
“Isso aqui resolve o problema ou apenas massageia meu ego?”
“Código que ninguém entende é bug esperando acontecer.”
“A solução certa no momento errado é, de certa forma, a solução errada.”
Vivemos cercados por conteúdos de alto nível técnico, muitos deles escritos por profissionais que enfrentam desafios diferentes dos nossos. Sem contexto, aplicar essas soluções pode ser mais um problema do que uma vantagem.
Até mesmo ferramentas de IA podem sugerir arquiteturas excessivamente complexas, porque são alimentadas pelos mesmos conteúdos. Por isso, mais do que saber muito, é preciso saber quando aplicar o que se sabe.
No fim, o desafio não é só construir soluções sofisticadas, mas sim entregar valor com leveza, clareza e foco no que realmente importa. E isso, na Engenharia do Asaas, é um princípio que nos guia todos os dias.
Na minha experiência, quase todo projeto que deu errado não foi por falta de competência técnica da equipe, mas por falta de clareza no escopo. O escopo é como o mapa da viagem: define para onde vamos, quais paradas faremos e o que não faz parte do trajeto.
Lembro de um projeto em que a pressão para “começar logo a codar” era enorme. Eu insisti em parar algumas horas e escrever um Scope Statement simples: o que estava dentro, o que estava fora e quais seriam os critérios de aceitação.
Essa decisão evitou que, meses depois, o time fosse surpreendido por pedidos fora de contexto: o famoso scope creep.
Escopo na prática: produto vs. projeto
Uma das primeiras confusões que costumo ver é misturar product scope e project scope. Vou dar um exemplo real.
Certa vez, gerenciei um projeto para criar um aplicativo de vendas. O product scope dizia que o app teria login com biometria, catálogo de produtos e integração com pagamento.
Já o project scope era diferente: englobava tarefas como configurar ambiente, desenvolver APIs, criar testes automatizados, treinar o time de suporte e documentar o processo.
Essa distinção foi crucial para explicar para o cliente que “ter login biométrico” não significa apenas apertar um botão mágico — existe uma cadeia de trabalho por trás.
Como evitar a dor de cabeça do scope creep
Gerenciar escopo não é sobre travar mudanças, mas sobre controlá-las. Mudanças vão acontecer, e tudo bem.
A diferença está em ter processos claros: um WBS (Work Breakdown Structure) para dividir entregas, um registro de mudanças para aprovar ou rejeitar pedidos, e um baseline de escopo para medir impactos em prazo e custo.
No mesmo projeto do aplicativo, o cliente pediu no meio do caminho a inclusão de “notificações push segmentadas por perfil”. Ao invés de simplesmente aceitar, seguimos o processo de controle: avaliamos impacto no cronograma e no orçamento, discutimos prioridades e só então aprovamos.
O cliente entendeu que não era “birra do gerente”, mas uma forma de manter previsibilidade.
No fim, o aplicativo foi entregue no prazo, com qualidade, e o cliente confiou ainda mais no time porque percebeu que havia método e transparência.
Técnicas de Scope Management
Para apoiar esse controle do escopo, existem diversas técnicas de Scope Management. Nem todas são usadas ao mesmo tempo em um projeto, mas sempre aplicamos pelo menos algumas delas:
Scope Statement
Documento simples que descreve o que está dentro e fora do escopo.
Exemplo: “O sistema terá integração com cartão de crédito, mas não com criptomoedas nesta fase.”
WBS (Work Breakdown Structure)
Quebra do trabalho em partes menores e entregáveis.
Exemplo: Projeto de e-commerce → 1. Catálogo, 2. Carrinho, 3. Pagamento, 4. Logística.
Dicionário da WBS
Complemento da WBS com descrição detalhada de cada item.
Exemplo: “3.1 API de Pagamento → implementar integração com Stripe, com autenticação via token.”
Change Control Process
Fluxo formal para aprovar, rejeitar ou postergar mudanças.
Exemplo: Cliente pede “dashboard em tempo real”. O time analisa impacto em prazo/custo antes de incluir.
Baseline de Escopo
Versão “congelada” do escopo aprovada pelos stakeholders, usada como referência.
Exemplo: contrato fechado com as funcionalidades definidas; qualquer mudança passa pelo processo de controle.
Requisitos SMART
Especificar requisitos Específicos, Mensuráveis, Atingíveis, Relevantes e Temporais.
Exemplo: “Gerar relatório mensal em PDF até o dia 5 de cada mês” (claro, testável e com prazo).
Protótipos e Wireframes
Usados para validar rapidamente expectativas de stakeholders e evitar mal-entendidos.
Exemplo: mostrar tela de login mockada antes de desenvolver.
Matriz de Rastreabilidade de Requisitos
Conecta cada requisito com entregáveis, testes e aprovações.
Exemplo: requisito de “login biométrico” → tarefa “API de autenticação” → caso de teste “validar impressão digital”.
MoSCoW Prioritization
Classificação de requisitos em: Must Have, Should Have, Could Have, Won’t Have.
Exemplo: Em MVP de app, “login” é Must, “dark mode” é Could.
Workshops com Stakeholders
Encontros práticos para mapear expectativas e validar escopo colaborativamente.
Exemplo: rodar uma sessão de brainstorming para listar o que “não” entra no projeto.
Lembre-se que o escopo é a linha que separa o sucesso do caos. Quando planejado, documentado e controlado de forma clara, ele dá segurança ao time e confiança ao cliente. Não é burocracia: é sobrevivência para quem quer entregar valor de verdade.
👉 E você, já passou por algum projeto em que o escopo foi mal definido? Como lidou com isso? Se quiser trocar experiências estou no linkedin: https://www.linkedin.com/in/fontx/
Ao pensarmos no mercado brasileiro de desenvolvimento de software, apesar da grande oferta de oportunidades, a concorrência está cada vez mais acirrada. Nesse cenário, conquistar a posição de dev sênior exige muito mais do que tempo de mercado: é resultado de evolução técnica, visão estratégica e maturidade profissional.
Atingir a senioridade significa ser capaz de resolver quase qualquer tipo de problema com pouca ou nenhuma supervisão. É ter autonomia para fazer as perguntas certas, entender novos desafios e prever possíveis falhas antes mesmo que aconteçam. Essa preparação é o que garante a entrega de soluções eficientes, bem documentadas e testadas, inclusive facilitando a manutenção futura.
Não é uma missão fácil, mas longe de ser impossível. Para o dev júnior, o ponto-chave para cumprir essa jornada deve ser, acima de tudo, abraçar o escopo naturalmente mais “simples” da sua função, o que inclui: atuar sobre um conjunto limitado de problemas, contar com orientação para lidar com tarefas mais difíceis e trabalhar com poucas linguagens.
Essa etapa não deve ser vista como um obstáculo, e sim como a fundação da carreira.
Olhar estratégico
Já no caminho para se tornar sênior, o desenvolvedor também precisa saber que a execução não pode ser o seu único objetivo. “Fazer funcionar” não é o suficiente, é preciso garantir que funcione bem, hoje e daqui a dois anos, mesmo após mudanças no sistema ou crescimento da base de usuários.
Ou seja, o que na fase de júnior era apenas “seguir um passo a passo” se transforma em compreender o porquê cada decisão técnica é tomada e seus impactos. Isso passa por escolhas que influenciam diretamente a escalabilidade, a performance e a facilidade de manutenção de um sistema.
Um desenvolvedor sênior considera, por exemplo, se a escolha de um framework pode limitar futuras expansões ou se uma determinada abordagem de banco de dados pode se tornar um gargalo. É esse tipo de leitura que permite entregar soluções sustentáveis, que continuam eficientes a longo prazo.
Poder de adaptação
Outra percepção importante de quem quer se tornar sênior é que a tecnologia não para de se transformar. Quem quer se manter relevante precisa ter curiosidade para aprender e explorar conceitos além da sua especialidade principal.
Isso envolve, por exemplo: estudar novas linguagens e aplicações de IA (inteligência artificial); entender diferentes paradigmas de programação; experimentar padrões de arquitetura modernos; e se atualizar sobre ferramentas que podem otimizar o fluxo de trabalho.
Essa adaptabilidade também significa saber escolher a tecnologia certa para cada contexto, em vez de aplicar sempre a mesma solução. Um sênior entende quando vale a pena adotar uma ferramenta emergente e quando é melhor manter algo mais consolidado, equilibrando inovação e estabilidade.
Nesse contexto, ganha força o conceito do “Dev em T”, o profissional que combina um conhecimento profundo em uma área específica (a barra vertical do “T”) com uma base mais ampla em diversas outras tecnologias e competências correlatas (a barra horizontal). Ser um “Dev em T” significa, por exemplo, ser um especialista em back-end, mas também compreender o suficiente sobre front-end, DevOps e negócios para colaborar de forma eficaz e ter uma visão holística do produto. Para quem deseja explorar mais a fundo essa e outras trilhas de carreira em tecnologia, o guia de carreiras TechGuide.sh da Alura oferece um mapa completo sobre as habilidades necessárias para diversas áreas.
Confiança como reconhecimento
No final das contas, alcançar a senioridade é uma grande conquista? Com certeza, mas o júnior em busca desse objetivo também precisa entender que não se trata apenas de um cargo mais alto. O verdadeiro reconhecimento desse crescimento é a conquista da confiança do time, das lideranças e do próprio mercado para tomar decisões críticas, conduzir projetos e influenciar resultados
A consistência de entrega de valor e de postura vem muito antes do nome que aparece no crachá.
A segurança é um elemento fundamental do desenvolvimento de software, mas os times nem sempre têm tempo, recursos ou os treinamentos necessários para proteger seus códigos devidamente. Ainda assim, as pessoas desenvolvedoras são a primeira linha de defesa de qualquer aplicação e podem contar com as ferramentas gratuitas do GitHub Copilot como grandes aliadas na proteção do código aberto e evolução das próprias habilidades.
A inteligência artificial não é somente capaz de escrever códigos, mas também entende o que está sendo desenvolvido, auxiliando a tornar o processo mais seguro quando devidamente configurada. Ela atua como um copiloto, exatamente como o nome indica, respondendo perguntas e analisando projetos para encontrar potenciais brechas de segurança enquanto sugere correções e mudanças para melhor proteção.
Com o GitHub Copilot adicionado à sua IDE de preferência, é possível, por exemplo, selecionar um código pré-existente e pedir ao agente de IA que analise, indicando possíveis vulnerabilidades ou sugerindo correções. Com o comando /fix, a tecnologia pode dar sugestões gerais sobre o trecho ou avaliar arquivos de um repositório. Ela também pode oferecer contexto ou indicações especializadas a partir de prompts como “qual a superfície de ataque?” ou “é possível fazer isso de uma maneira mais segura?”, aumentando ainda mais a qualidade e segurança dos projetos.
A tecnologia não auxilia apenas por meio da IA generativa, mas também pode funcionar como um agente de código integrado diretamente ao GitHub, que começa a trabalhar assim que uma issue é atribuída ao Copilot ou ativada por meio de prompt no VS Code, por exemplo. O agente cria um ambiente de desenvolvimento totalmente customizável, com o auxílio do GitHub Actions, e usa modelos de ponta que se destacam em tarefas de baixa a média complexidade em bases de código bem testadas, desde a adição de funcionalidades e correção de bugs até testes extensos, refatoração de código e aprimoramento da documentação. Dessa forma, é possível delegar as tarefas demoradas, mas entediantes, ao agente, enquanto a pessoa desenvolvedora foca no trabalho interessante.
O agente de IA está disponível em aplicações como Visual Studio Code, JetBrains IDEs, Neovim, XCode e GitHub Mobile, além de terminais e no github.com. Seu código pode ser ainda mais protegido com o uso de outras ferramentas de segurança também disponíveis no GitHub:
Dependabot
Ao trabalhar em um repositório público no GitHub, a pessoa desenvolvedora pode receber um pull request de um usuário chamado Dependabot. Esta ferramenta do GitHub verifica se as dependências de software da sua aplicação estão atualizadas e livres de vulnerabilidades.
Para ativar ou desativar o Dependabot, clique na aba Configurações do seu repositório. Role a página e selecione Segurança de Código no menu lateral esquerdo. Nessa seção, você encontrará todas as opções relacionadas ao recurso, onde também é possível ativar ou desativar alertas e atualizações automáticas.
Escaneamento de códigos e CodeQL
Recurso disponível no GitHub Actions, o escaneamento de códigos detecta automaticamente erros e vulnerabilidades comuns. É altamente recomendado habilitar a análise com CodeQL, um importante aliado para uma programação mais segura.
Para ativar o recurso, clique no botão Configurar e selecione Padrão no menu que aparece. Depois, clique em Habilitar CodeQL para que o GitHub Copilot passe a escanear seu código automaticamente toda vez que fizer um commit ou criar um pull request. A ferramenta também realiza checagens periódicas e, quando alguma vulnerabilidade é encontrada, a pessoa desenvolvedora é notificada para correção caso os alertas estejam devidamente configurados.
Copilot Autofix
Caso queira que o GitHub Copilot sugira correções automaticamente para as vulnerabilidades encontradas, ative o Copilot Autofix. Ele está localizado na mesma página de segurança mencionada acima, após o botão de ativação do CodeQL.
Com essa opção habilitada, o agente é executado assim que detectar um problema e cria um pull request com a correção sugerida. Você poderá revisar e aceitar a sugestão, sem precisar realizar a alteração manualmente.
Escaneamento de credenciais
Outro recurso essencial é o escaneamento de credenciais, também localizado no final da página de opções de segurança. O recurso gratuito para repositórios públicos permite que o GitHub verifique e sinalize qualquer dado sensível exposto no código, como senhas, tokens de API e chaves de acesso.
Inserir esse tipo de dado diretamente no código representa um alto risco de segurança. Quando habilitado, o escaneamento de credenciais checa os repositórios por tipos conhecidos de credenciais e alerta os administradores caso sejam detectados.
A segurança é um campo complexo, mas com esses passos, as pessoas desenvolvedoras podem proteger toda a jornada do código. Isso vale, principalmente, para quem não é expert no assunto, com o agente de IA e as ferramentas de segurança colaborando diretamente para que a programação siga as melhores práticas.
Quando devemos ser mais inteligentes sobre acoplar nossos tipos a outros tipos? Quando é que repetir código vale a pena?
Quando eu converso com alguém sobre TypeScript, uma das coisas que inevitavelmente vem à tona é a pergunta:
Quando a gente tem que criar um tipo novo ou quando a gente tem que derivar a partir de outro tipo?
Pra quem está na Formação TS, sabe que eu sou muito fã de derivar tipos, escrever em um único lugar e utilizar variações desse tipo em todos os outros lugares. É uma aplicação do princípio do DRY (don´t repeat yourself) que podemos aplicar tanto para código quanto para tipos. E quando eu digo um tipo derivado eu estou falando coisas desse tipo:
interface Person {
name: string;
id: string;
}
interface Employee extends Person {
salary: number;
}
Veja que estamos estendendo uma interface para poder criar uma segunda interface, que contém os tipos da primeira, mas não é exatamente igual. E isso acontece não só com interfaces, mas com qualquer outro tipo que dependa de outro tipo, com em union types e intersection types:
type Person = { name: string, id: string }
type Employee = Person & { salary: number }
type Cat = {
type: 'cat';
meow: () => void;
}
type Dog = {
type: 'dog';
woof: () => void;
}
type Animal = Cat | Dog;
Tipos derivados não podem modificar os tipos originais, mas podem modificar os tipos que são derivados deles, por exemplo, Employee não pode modificar Person, mas se outro tipo estender Employee, então ele pode modificar esse tipo porque se qualquer uma de suas propriedades mudar, o outro tipo será modificado também.
Quando isso acontece a gente diz que o tipo é acoplado, porque o tipo derivado depende do tipo original.
Vale a pena acoplar?
Tipos acoplados, ou derivados, são ótimos quando a gente está tratando do mesmo “domínio”, por exemplo, como eu comentei lá no último artigo sobre enums, geralmente quando estamos usando enums, uma opção é criar objetos com as const e ai criar a lista de valores como um tipo separado:
const envs = {
PROD: 'production',
DEV: 'development',
TEST: 'test'
} as const
type Envs = (typeof envs)[keyof typeof envs]
Se a gente não fizesse isso, iríamos ter que duplicar todos os valores desse objeto duas vezes, o que criaria duas fontes de informação que a gente precisaria manter.
Outro caso que é muito interessante derivar tipos é quando estamos lidando com variações de tipos de entrada em uma API, por exemplo, temos um payload para a criação de um usuário:
interface User {
id: string
name: string;
age: number;
}
type UserCreate = Omit<User, 'id'>
Neste caso faz sentido termos uma derivação porque nossa entidade usuário tem um ID sempre quando ele está criado, mas, quando queremos criar um usuário, não precisamos mandar um ID. O mesmo vale para quando vamos atualizar um usuário, não podemos mandar o ID e todos os objetos podem ser opcionais:
type UserUpdate = Omit<Partial<User>, 'id'>
Ou seja, faz muito sentido derivar se a gente está tratando da mesa entidade e ambos os tipos são parte de um todo que não faz sentido se são separados. A grande vantagem disso é que você pode modificar o tipo em um lugar e ele vai ser automaticamente propagado para todo o projeto, o que facilita muito na hora de fazer o desenvolvimento, mas essas cadeias de derivação podem ser mais complicadas quando ficam muito longas porque podem ter efeitos indesejados.
Quando desacoplar faz mais sentido?
Ao contrário do que estamos acostumados, desacoplar tipos faz bastante sentido quando estamos lidando com partes dos dados de um tipo completo, por exemplo, uma função que leva apenas o nome do usuário, ou então apenas o nome e a idade.
import type { User } from 'types'
function calculate(age: User['age']) {}
Esse parece um exemplo simples, mas veja que agora todo o arquivo depende desse tipo na pasta types, se ele mudar de lugar, todos os arquivos que dependem dele vão sofrer uma mudança, além de que estamos desacoplando uma única propriedade para um uso que pode não ser de conhecimento do nosso usuário.
Se você está em dúvida, imagine a seguinte pergunta: “Se eu derivar esse tipo, quando o tipo original mudar, vai soar estranho?”
Se a resposta for sim, desacople o tipo. E o que é “soar estranho”, por exemplo, se alterarmos um arquivo de utilitário para calcular a idade de um usuário para exibir em uma tela, não deveríamos ter que modificar o nosso banco de dados para a mesma coisa.
No final é tudo uma questão de observar o trabalho que você vai ter para manter no futuro, talvez a questão certa para se perguntar é:
Se eu desacoplar, vou ter mais trabalho para manter?
Então a regra base é a seguinte:
Se, quando um tipo alterar, o outro precisa ser alterado, então acople.
Se um tipo derivado gerar mais trabalho para você quando alterado, desacople.
O Obsidian é uma ferramenta poderosa para gerenciamento de notas, e manter um backup automatizado é essencial para a segurança dos seus dados. Neste post, vou mostrar como configurar um backup automático do seu vault do Obsidian usando Git no macOS, com execução programada duas vezes ao dia.
Primeiro, vamos criar um script que realizará o backup. Crie um arquivo chamado cronObsidian.sh no diretório de sua preferência aqui vou utilizar o seguinte ~/git:
Verifique as permissões do script (deve ser executável)
Confirme se os caminhos no arquivo plist estão corretos
Verifique os arquivos de log para identificar possíveis erros
Certifique-se de que o Git está configurado corretamente
Conclusão
Com essa configuração, seu vault do Obsidian será automaticamente versionado e backup-ado duas vezes ao dia. Isso garante que suas notas estejam sempre seguras e sincronizadas com seu repositório remoto.
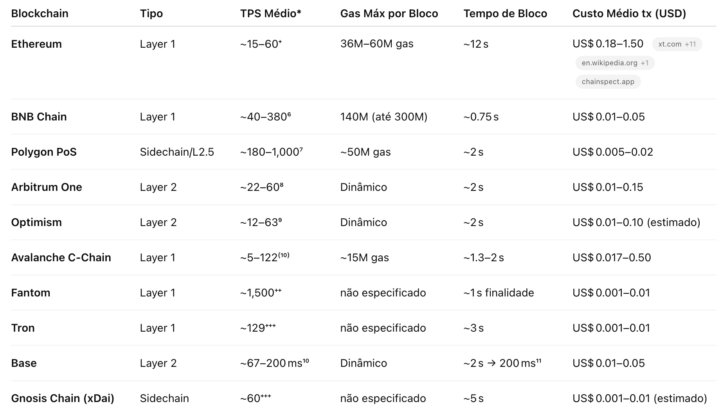
Uma pergunta recorrente que recebo de alunos e clientes de consultoria é sobre qual a melhor rede blockchain para fazerem deploy dos seus smart contracts. Infelizmente não existe uma resposta definitiva para esta pergunta, já que não existe uma única rede que supere todas as outras em todos os aspectos de qualquer projeto. Enquanto temos alguns projetos que são bem recorrentes, como tokens ERC20, coleções ERC721, etc, mesmo neles temos aspectos a serem considerados na hora de escolher a blockchain-alvo.
Não apenas isso, escolher a blockchain certa para um projeto Web3 é uma decisão estratégica fundamental. A escolha impacta diretamente nos custos de transação, velocidade e UX, segurança, compatibilidade com carteiras, bridges, oráculos, adoção e liquidez do ecossistema e muito mais.
Dito isso, no artigo de hoje vou explorar alguns destes aspectos, usando exemplos de redes reais para ilustrar os tópicos e te ajudar no entendimento. Mas atenção: a tendência é que você não deva usar os dados específicos que trouxe aqui, mas sim os conceitos, já que esse é um mercado que está evoluindo muito rapidamente e as características de cada rede mudam a cada nova versão.
Vamos lá!
Stack de Tecnologia
A primeira coisa que costumo olhar é a stack de tecnologias do projeto. Se ele foi feito para SVM (Solana Virtual Machine), não há o que discutir, terá de usar a rede Solana para o deploy. Mas na imensa maioria dos casos, aproximadamente 80% deles segundo pesquisas (SolidityLang, Electric Capital e outras), os projetos são para redes EVM (Ethereum Virtual Machine), e portanto requerem a escolha de uma rede que suporte esta VM, que são várias: BNB Chain, Avalanche, Polygon, Arbitrum, Optimism e claro, a própria Ethereum Mainnet, só para citar alguns exemplos.
“Luiz, então se eu não quiser me estressar com a escolha da rede, é só trabalhar com Solana?”
Essa escolha, se feita de forma preguiçosa, apenas por essa razão, vai te gerar uma série de outros problemas. A rede Solana tem sim as suas qualidades, como o baixo custo de transação ($0.00025) e um tempo de bloco de 400ms (embora tenha outras redes parecidas nesse quesito), mas sofre de outros problemas como ecossistema ainda pequeno (o que afeta materiais de apoio e mão de obra especializada) , curva de aprendizado alta e um histórico de problemas que geraram até interrupção de seus serviços (aqui, aqui, aqui,aqui e aqui). Não me entenda mal, toda rede tem seus problemas, estou apenas trazendo contrapontos à euforia que alguns devs depositam em cima da rede Solana.
Dito isso, se optou pela stack SVM, não tem outra opção senão seguir com a Solana e o artigo não irá lhe ajudar em nada a partir daqui. Outras redes também “sofrem” do mesmo problema, como Sui e Near, enquanto que algumas como Polkadot apostam em tentar manter compatibilidade com a sua stack + suporte a EVM através de “parachains”. Continuando a leitura, assumirei que seu projeto é EVM ou vai optar por EVM para o desenvolvimento dele.
Nada contra as demais, mas EVM é a minha especialidade e onde posso ajudar mais com informações e exemplos para ilustrar os tópicos.
Segurança e Transparência
Satoshi Nakamoto e outros autores introduzem o conceito de Trilema da Blockchain: Segurança, Escala (performance) e Descentralização. Ter uma rede perfeita nstes três aspectos seria conceitualmente impossível visto que eles são antagônicos. Não quer dizer que priorizando dois deles o terceiro aspecto seria completamente ignorado, mas que o trilema era uma realidade indiscutível e que, no caso da rede do BTC, foi priorizado segurança e descentralização, o que impactou diretamente a performance da rede, mesmo apesar de melhorias feitas de lá para cá. Pra você ter uma ideia, o tempo de bloco da rede BTC é de aproximadamente 10 minutos, o que indica que ela pode levar até esse tempo para registrar sua transação. Além disso, enquanto que o custo de uma transferência simples gira em torno de $0,50 a $2,50, existem recordes registrados de até $50 de taxa em picos de congestionamento, o que mostra novamente desafios de escala.
Novamente, o objetivo aqui não é denegrir a rede do BTC, que é a maior, mais segura e mais estável dentre todas as redes em atividade, sem downtime desde seu lançamento em 2009. Mas sim, te trazer que a escolha por segurança máxima traz impactos negativos em descentralização ou escala. É por esta razão, de escala (tanto em tempo quanto em custos), que a rede do BTC, mesmo com as gambiarras que alguns devs fazem para criar tokens e coleções NFT nela, não é adequada para nenhum projeto web3, servindo única e exclusivamente para as transações da criptomoeda de mesmo nome, conforme seu objetivo original.
Analisando outras redes no quesito segurança, temos que entender a diferença fundamental entre redes Layer 1 e redes Layer 2. Redes Layer 1, como Ethereum Mainnet e BNB Chain, são redes blockchain tradicionais, que vão recebendo as transações, processando elas e registrando as alterações de estados no seu storage, replicando as alterações entre seus nós. Elas são as mais seguras e confiáveis, já que toda transação registrada nela segue as regras comuns à todas blockchains como imutabilidade, auditabilidade, etc. Se o seu projeto exige o máximo nesses dois quesitos, você provavelmente vai querer estar em uma rede L1.
Redes L2 são camadas de software blockchain adicionais a uma L1, ou seja, elas operam em cima de outra blockchain tradicional. A Polygon por exemplo, é uma L2 da Ethereum Mainnet, enquanto que a opBNB é uma L2 da BNB Chain. Redes L2 são muito mais rápidas e baratas que L1 e isso não é por acaso, já que redes L2, no geral, fazem duas coisas bem diferentes das blockchains tradicionais: elas processam as transações fora da blockchain L1 (offchain) e agrupam as mesmas em grandes conjuntos (rollups) para serem registradas apenas uma vez. Essas duas mudanças, em conjunto, fazem com que o ganho de velocidade e economia de taxas seja gritante, no entanto trazem um risco maior à segurança, integridade e auditabilidade das transações.
Resumidamente, as redes L2 não registram todas transações na rede L1 adjacente, mas apenas snapshots ou resumos delas, dentro de smart contracts da própria rede L2. Assim, um saldo de token que você tem na L2 não é refletido na L1 e vice-versa e sequer você verá as mesmas transações em ambas, com exceção de saques e depósitos da moeda nativa da rede. Assim, redes L2, na minha opinião, não são interessantes para protocolos onde a segurança e transparência sejam itens críticos, como grandes tesourarias e protocolos DeFi que lidam com grandes transações (em valor nominal), mas são muito interessantes para protocolos que exijam performance alta e custos baixos, como veremos a seguir. Vale ressaltar que algumas redes L2, como a Polygon, buscam evitar problemas de segurança adicionando recursos específicos para esse fim, se chamando de L2.5 (ou sidechain) por causa disso, obviamente impactando diretamente na performance como veremos a seguir.
Performance e UX
Quando analiso a performance necessária a um projeto web3, tenho em mente um fator crucial: a experiência do usuário (UX). E a experiência do usuário é impactada diretamente pelo tempo que ele tem de esperar para que algo aconteça na sua aplicação, então vamos falar um pouco de tempo agora.
O tempo pode ser expressado pelo tempo de bloco de uma rede (em segundos) e pelo seu tamanho de bloco (em gás), o que nos leva à sua vazão (em TPS ou Transações por Segundo). Por exemplo, a rede BNB Chain, desde o dia 30/06/25, possui um tempo de bloco de 0.75 segundos e um tamanho de bloco de até 140M de gás. Com cada transferência simples consumindo 21k gás, temos a possibilidade teórica de mais de 6k transações por bloco ou um TPS teórico de mais de 8k/s. Eu digo teórico porque na prática existem mais fatores (como a validação e propagação) e não é tão simples assim, o TPS real da BNB Chain é de 2k/s, com meta de chegar a 5k/s em breve. Nada mal para uma rede L1, certo?
Pegando outro exemplo, a rede Ethereum Mainnet possui tempo de bloco de 12 segundos (com propostas para chegar a 6s), tamanho de bloco de 30M de gás e vazão de 20 TPS. Sim, até 20 transações por segundo, sendo que a média é 15 TPS. Mas antes que você pense mal da Ethereum, lembre-se: ela é a segunda maior rede do mundo e isso impacta na descentralização e na segurança também. Mas é fato que se UX for algo relevante para você, como no caso de games web3, ela não será a rede mais escolhida.
E antes que você ache que basta escolher qualquer rede L2 e está tudo resolvido em termos de performance, saiba que a rede Polygon por exemplo, uma famosa L2 da Ethereum Mainnet, possui um tempo de bloco de 2 segundos, ou seja, bem mais que o dobro da BNB Chain. Mas e uma L2 da BNB Chain? Será que não performaria melhor? Neste caso sim, a opBNB possui um tempo de bloco de 500ms, bem próximo do que temos na Solana por exemplo (400ms), sem abrir mão do ecossistema EVM que é muito maior que o SVM.
Custos de Transações
Saber o custo médio de transações em uma rede é um fator crucial principalmente em protocolos que envolvam micropagamentos, redes sociais e outros. Não há toa este costuma ser o principal aspecto analisado pelos desenvolvedores quando estão decidindo a blockchain onde vão colocar seus smart contracts e ingenuamente muitas vezes é o único quesito. Digo ingenuamente pois como citei antes, existem outros fatores além deste que são tão importantes quanto, dependendo do tipo de projeto que está desenvolvendo.
O custo de transações depende de fatores como complexidade da mesma (de acordo com código no próprio smart contract), custo do gás (melhor explicado aqui), congestionamento da rede e cotação da moeda nativa da rede e portanto é o elemento que mais varia entre os projetos e também com o passar do tempo, sendo o mais difícil de dimensionar previamente. Para resumir os custos das 10 maiores redes em 2025, pedi ao ChatGPT que montasse essa tabela abaixo e embora eu não tenha revisado campo a campo com os números oficiais de cada rede, me parece estar coerente.
Vale uma menção honrosa à opBNB que não figura no top 10 redes mas que é a única L2 da BNB Chain, sendo que as demais L2 são em cima da Ethereum. Usando a mesma base da Optmism, ela consegue um tempo de bloco de 500ms, mais de 4k TPS e custo médio de $0.005 por transação.
No entanto, note que não importa o quão barata seja uma rede, se o seu código for complexo demais (em tempo e espaço), ele vai gerar transações caras, então antes de qualquer coisa, faça o seu código o mais econômico possível, conforme dicas que já passei antes.
Ecossistema e Histórico
E por fim, dois aspectos muitas vezes negligenciados na hora de escolher a melhor blockchain para seu projeto: tamanho do ecossistema e longevidade da blockchain (histórico). Como citei antes, muitas vezes os devs e empreendedores olham unicamente para o custo e/ou para a velocidade da blockchain e acabam se esquecendo de se perguntar coisas como:
há quantos anos esta blockchain está no mercado?
qual a base de usuários ativo dela no país do meu projeto? E no mundo?
ela já enfrentou problemas no passado (segurança, performance, etc)? Como lidou com eles?
que outros projetos bem sucedidos estão deployados nesta rede? Algum parecido com o meu?
como funciona a governança dessa rede? E seu suporte?
Mais um fator que não coloquei aqui mas sei que devs buscam são os grants ou incentivos financeiros que algumas redes dão visando atrair novos projetos. Esses benefícios são uma faca de dois gumes: ao mesmo tempo que é ótimo levantar uma grana a fundo perdido no início do seu projeto, são somente as blockchains mais novas e com menores ecossistemas que saem dando dinheiro para qualquer projeto. Quanto maior e mais velha é a rede, menos ela vai precisar “pagar” para expandir seu portfólio. Então sempre pese isso: a grana que você vai ganhar agora dessa nova rede realmente valerá a pena no longo prazo? Se sim, inclua o quesito “grants” na sua análise, caso contrário, fuja dele.
Outro fator mais raro, mas que pode ser o caso, é se o seu projeto possui sinergia ou até dependência de outro projeto existente. Sei lá, ele vai fazer algo na Uniswap por exemplo, então precisa estar em uma das redes onde a Uniswap tem deploy. E já que falei em Uniswap, tem também os casos de projetos tão grandes que possuem deploy em mais de uma rede, o que certamente dificulta a gestão mas aumenta consideravelmente a habilidade de captar usuários.
Essa ideia que fiz no tópico passado, de montar uma tabela, é excelente para você conseguir ver mais claramente as diferenças entre as redes que você cogita utilizar e quais são os pontos fortes e fracos de cada uma considerando o peso que você dá a cada aspecto. E lembrar-se disso é muito importante: o que o projeto A precisa é diferente do projeto B, por isso que quanto mais sêniors nós somos, menos certeza nós temos e mais análises fazemos antes de tomar uma decisão.
Espero que o artigo tenha ajudado.
Vamos pra cima que esse mercado é nosso!
Se preferir, você pode assistir ao vídeo abaixo ao invés de ler.
O Angular continua a evoluir, introduzindo melhorias significativas para desenvolvedores. Desde o Angular v17, a CLI do Angular adotou um construtor baseado em ESBuild , substituindo a solução Webpack original . Além disso, o uso de módulos não é mais necessário, pois o Angular agora prioriza componentes autônomos.
No âmbito dos micro frontends (MFE), a Federação de Módulos desempenha um papel fundamental ao permitir a criação de aplicações web modulares, escaláveis e sustentáveis, compondo partes desenvolvidas de forma independente em tempo de execução. Essa abordagem foi introduzida pela primeira vez no Webpack 5, trazendo o conceito de microsserviços para o frontend.
Federação Nativa é uma técnica emergente que utiliza funcionalidades nativas do JavaScript e módulos ECMAScript (ESM) para implementar micro frontends sem ferramentas de build como o Webpack . Ela utiliza importações dinâmicas e o sistema ESM para federar módulos, simplificando o processo.
Com a migração do Angular CLI do Webpack para o ESBuild, surgem novos desafios na adoção da arquitetura MFE. É aqui que a Federação Nativa se torna particularmente relevante, especialmente para projetos que utilizam Angular v17 ou versões mais recentes.
Neste tutorial, criaremos um MFE simples usando Angular e Native Federation, utilizando o @angular-architects/native-federationpacote para agilizar o processo de desenvolvimento.
Comece criando um novo espaço de trabalho Angular para hospedar seus diferentes MFEs. Certifique-se de ter a CLI Angular instalada localmente e execute:
ng new angular-mfe-native-federation --create-application=false
Isso gera um espaço de trabalho limpo para desenvolver vários projetos usando a arquitetura MFE.
A imagem a seguir é a saída do comando anterior:
Criando os aplicativos/projetos Angular
Em seguida, gere os aplicativos. Criaremos um Shellaplicativo e um Productsaplicativo (nosso primeiro MFE). Para simplificar, vamos nos limitar a esses dois por enquanto.
Para gerar o aplicativo Shell, execute:
ng generate application shell --prefix app-shell
Você deverá ver um projeto recém-criado:
Agora, repita o comando para o Productsaplicativo:
ng generate application products --prefix app-products
Agora você tem dois aplicativos em seu espaço de trabalho.
Adicionando Material Angular
Para ajudar a estilizar os aplicativos, usaremos o Angular Material . Use o seguinte esquema:
ng add @angular/material
Você pode encontrar erros, então certifique-se de que o Angular Material também seja adicionado a cada projeto individualmente:
ng add @angular/material --project shell
ng add @angular/material --project products
Corrigindo os estilos para cada projeto
Se os estilos não forem exibidos corretamente após adicionar o Material Angular, abra o angular.jsonarquivo e verifique se styles.scsso tema do Material selecionado está listado:
É uma barra de ferramentas de materiais simples com um ícone de página inicial que nos permite voltar à página inicial e um botão que permite ao usuário navegar até o aplicativo Produtos.
O header.component.tsarquivo ficará parecido com o seguinte:
import { Component } from '@angular/core';
import { MatButtonModule } from '@angular/material/button';
import { MatIconModule } from '@angular/material/icon';
import { MatToolbarModule } from '@angular/material/toolbar';
import { RouterLink } from '@angular/router';
@Component({
selector: 'app-shell-header',
imports: [RouterLink, MatIconModule, MatToolbarModule, MatButtonModule],
templateUrl: './header.component.html'
})
export class HeaderComponent { }
Estamos importando os módulos Material necessários. Como este componente está sendo usado apenas para roteamento, não precisamos adicionar nenhuma lógica, pois o Angular cuidará disso para nós. E como não precisamos de nenhum CSS personalizado para este exemplo, também podemos excluir o header.component.scssarquivo, juntamente com sua entrada no arquivo HeaderComponent.
Criando um componente Home
Em seguida, gere uma página inicial básica que pode ser exibida por padrão quando carregamos nosso aplicativo Angular:
ng g c header --project shell
Este componente exibirá um Cartão de Material com a palavra “Casa”. Aqui está o conteúdo do home.component.tsarquivo:
import { Component } from '@angular/core';
import { MatCardModule } from '@angular/material/card';
@Component({
selector: 'app-shell-home',
imports: [MatCardModule],
template: `
<mat-card appearance="outlined">
<mat-card-content>Home</mat-card-content>
</mat-card>
`
})
export class HomeComponent { }
Vamos manter tudo simples neste exemplo e, claro, você pode adicionar um design bacana para sua página inicial.
Agora podemos passar para a aplicação dos produtos.
Configurando o aplicativo MFE1 (remoto)
Transforme o productsprojeto em um MFE:
ng g @angular-architects/native-federation:init --project products --port 4201 --type remote
Este projeto será executado na porta 4201. Ajuste a porta projects/shell/public/federation.manifest.jsontambém:
O Angular não possui uma API que nos permita carregar módulos remotos. É aí que @angular-architects/native-federationentra o pacote que instalamos anteriormente.
Este pacote nos permite carregar preguiçosamente um componente remove usando o loadRemoteModulerecurso. Podemos usá-lo para carregar preguiçosamente um componente independente usando a loadComponentfunção da API Angular.
Executando o Shell e o MFE1 (Produtos)
Por fim, vamos executar nosso aplicativo localmente para ver o MFE em ação:
ng serve shell
ng serve products
Precisamos abrir dois terminais e executar cada ng servecomando. Depois, podemos abrir nosso aplicativo usando :http://localhost:4200
E se navegarmos até a /productsrota, devemos ver nossos produtos MFE:
Resumo
Nesta publicação, abordamos o processo de configuração de um espaço de trabalho Angular com micro frontends usando a Federação de Módulos. Criamos uma aplicação shell e uma aplicação remota de produtos, integramos o Angular Material para estilização e configuramos a Federação Nativa para arquitetura modular. Por fim, configuramos o roteamento e testamos ambas as aplicações em execução local. Essa configuração básica permite aplicações web escaláveis e modulares usando os recursos de MFE do Angular.
Conheça o conceito de vibe coding e a transformação da programação com IA para converter ideias em aplicações funcionais
Foto: Reprodução/Freepik
Para desenvolvedores, o vibe coding é apontado como uma das principais tendências da programação, com potencial para transformar a área nos próximos anos. Se você acompanha tecnologia, sabe que conceitos assim não surgem do nada. Andrej Karpathy, especialista em inteligência artificial com passagem por empresas como Tesla e OpenAI, foi quem ajudou a popularizar essa abordagem.
Com essa técnica, qualquer ideia pode ser transformada em código executável apenas a partir de descrições em linguagem natural. Funciona porque a IA, por meio de modelos de linguagem avançados (LLMs), realiza a maior parte do trabalho.
Karpathy resume bem: “Você só sente a ‘vibe’ com a IA. Dá o comando, recebe o código, roda, vê o que não funciona, tenta de novo, faz uns ajustes, cola e tenta de novo. Não precisa de uma especificação detalhada. A especificação está na sua cabeça. Você simplesmente cria.”
E os números reforçam a tendência. Segundo a Y Combinator, cerca de 25% de suas startups usam IA para gerar 95% de todo o seu código. Para quem trabalha com tecnologia, esses dados mostram como o vibe coding já impacta a rotina de profissionais e equipes.
Como o vibe coding funciona
O processo é simples na teoria, mas poderoso na prática: substituir a escrita manual de código por uma conversa com a IA. Esse diálogo ocorre de duas formas principais:
1. Plataformas integradas de criação
Ferramentas como a Hostinger Horizons, por exemplo, permitem que o usuário descreva seu projeto em linguagem natural e receba a aplicação funcionando, sem interação direta com o código-fonte.
Com um comando como “criar um aplicativo de reservas com integração de calendário e envio automático de e-mails”, é possível gerar front-end e back-end prontos para testes. Essa abordagem é ideal para iniciantes e não desenvolvedores que precisam validar um protótipo rapidamente.
2. Assistentes de codificação
Assistentes baseados em IA, como GitHub Copilot, ChatGPT e DeepSeek, dão mais controle técnico. Nessa abordagem, o programador solicita trechos de código específicos e os integra manualmente ao projeto.
Essa combinação de automação e controle preserva o domínio sobre arquitetura, stack e integrações, ao mesmo tempo que acelera tarefas repetitivas e libera tempo para decisões estratégicas.
Em ambos os casos, o ciclo é iterativo e criativo:
Criar um prompt claro e objetivo.
Receber o código gerado pela IA.
Executar e validar o resultado.
Ajustar e refinar conforme necessário.
Por exemplo, um podcaster pode gerar clipes com IA, um criador pode enviar respostas de formulários diretamente para o Notion, e um freelancer pode configurar um chatbot para responder perguntas frequentes.
Para obter resultados melhores, vale caprichar nos prompts e ser bem específico. Em vez de escrever só “Crie um site”, tente algo como “Crie um site de uma página para um designer, incluindo portfólio, serviços e formulário de contato”. Quanto mais detalhes forem incluídos, mais próximo do esperado o aplicativo ficará.
Diferenças em relação à programação tradicional
Na programação tradicional, cada linha de código precisa ser escrita à mão, seguindo a sintaxe e as regras da linguagem. No vibe coding, o desenvolvedor funciona mais como um arquiteto de soluções, dizendo o que quer e deixando a IA cuidar da implementação inicial.
Essa diferença traz implicações claras:
O vibe coding é mais rápido para protótipos e MVPs, mas menos indicado para sistemas complexos que demandam alta otimização ou segurança crítica.
A codificação manual oferece maior controle e previsibilidade, enquanto a abordagem com IA é mais flexível e voltada a iteração rápida.
Muitos desenvolvedores experientes já usam o vibe coding como complemento, não substituto, aproveitando a IA para eliminar tarefas repetitivas e focar na resolução de problemas estratégicos.
Benefícios práticos para criadores e equipes
O vibe coding vai além de uma simples conveniência: ele muda a maneira de criar software, reduzindo o tempo entre a ideia e o produto final e permitindo que mais pessoas participem do processo. Entre os principais benefícios estão:
Velocidade – Protótipos e MVPs podem ser desenvolvidos em horas, não semanas.
Acessibilidade – Reduz barreiras para quem não tem formação em programação.
Foco criativo – Libera tempo para design, UX e definição de funcionalidades.
Iteração ágil – Permite testar hipóteses e ajustar funcionalidades em ciclos curtos.
Paridade de ferramentas – Pequenos negócios têm acesso a recursos antes restritos a grandes empresas.
Essa rapidez muda o jogo no mercado: ideias que antes ficavam só no papel agora podem ser testadas e aprovadas gastando bem menos.
Segurança e boas práticas
Apesar da facilidade, o código gerado por IA pode conter falhas ou vulnerabilidades. Por isso, boas práticas continuam indispensáveis:
Revisar todo o código antes de colocá-lo em produção.
Testar em ambientes isolados (sandbox) antes da implantação.
Implementar tratamento de erros e validação de entradas para evitar ataques comuns.
Manter backups de versões funcionais para facilitar reversões.
O vibe coding também muda como a gente pensa os projetos. Em vez de passar semanas planejando antes da primeira linha de código, dá para criar uma versão mínima, testar com usuários e ir ajustando com base no feedback.
Para quem trabalha em startups ou equipes ágeis, isso é uma mão na roda: permite mostrar um MVP validado a investidores antes de investir em uma solução completa.
Mas não dá para confiar só na IA. Saber escrever prompts claros e revisar com atenção o que ela entrega faz toda a diferença para o resultado final.
Desafios e limitações
Apesar do potencial, o vibe coding não é solução universal. Entre os principais desafios estão:
Qualidade inconsistente do código gerado, exigindo supervisão humana.
Limitações de contexto dos modelos, que podem não entender requisitos complexos de arquitetura.
Dependência de ferramentas externas, o que pode afetar a continuidade de projetos.
Questões de propriedade intelectual, ainda em debate quando o código é gerado por IA.
Esses pontos mostram que, embora seja uma revolução no acesso, o vibe coding ainda requer cautela e conhecimento técnico para uso profissional.
Tendências para os próximos anos
A expectativa é que, no curto prazo, a IA assuma cada vez mais tarefas repetitivas e estruturais. No médio e longo prazo, veremos múltiplos agentes de IA trabalhando juntos em tempo real, gerando código, testes automatizados e implantações seguras.
Segundo projeções, até 2026, cerca de três em cada quatro novos aplicativos serão criados com ferramentas sem código, adotando o vibe coding. Esse cenário mostra a transformação do papel do desenvolvedor, que precisará focar em validação, integração e inovação.
O vibe coding não é só uma técnica: é uma mudança cultural na forma de criar software. Ele permite que qualquer pessoa transforme ideias em produtos funcionais, independentemente do tamanho da equipe ou do orçamento.
Reduzindo o tempo entre concepção e execução, o vibe coding amplia a diversidade de soluções e acelera ciclos de inovação. Ao mesmo tempo, fortalece a presença digital como um diferencial competitivo.
Para quem atua no setor, entender e dominar essa abordagem se torna essencial. Quem se adapta cedo conquista vantagem estratégica, aproveitando a IA para liberar tempo e criatividade no desenvolvimento de soluções reais.