Neste artigo vou apresentar a biblioteca FastEndpoints, um framework minimalista usado para criar Web Apis na plataforma .NET
O FastEndpoints é uma biblioteca que tem a proposta de simplificar a criação de endpoints de Web API no .NET, utilizando uma abordagem baseada em classes e métodos declarativos. Ele elimina a necessidade de configurar controladores (Controllers) e roteamentos de maneira tradicional, tornando o desenvolvimento mais rápido e com menos código.
.NET
A criação de APIs da Web com o ASP.NET Core pode envolver muito código repetitivo, especialmente ao lidar com controladores, roteamento e vinculação de modelos. O FastEndpoints é uma biblioteca leve que simplifica esse processo, permitindo que você defina endpoints com o mínimo de código e ótimo desempenho.
Ela segue o padrão REPR – Request-Endpoint-Response – e oferece os seguintes vantagens :
Menos código boilerplate:
Não há necessidade de criar controllers, actions e configurar roteamentos manualmente.
Desempenho otimizado:
Menor sobrecarga em comparação ao MVC padrão da ASP.NET Core.
Desenvolvimento mais rápido:
Criação de endpoints de maneira declarativa, com validações e injeção de dependência simplificados.
Validações integradas:
Suporte embutido para validação de modelos usando FluentValidation.
OpenAPI/Swagger:
Suporte nativo para gerar documentação da API
Usando FastEndpoints
Para usar o FastEndpoints basta criar um projeto ASP.NET Core e incluir o pacote FastEndpoints: dotnet add package FastEndpoints
O FastEndpoints adota uma abordagem Handler-Based (baseada em manipuladores) em vez de usar controladores convencionais do ASP.NET Core MVC, para simplificar a criação de APIs REST.
O FastEndpoints utiliza a middleware pipeline do ASP.NET Core e o recurso de routing endpoint introduzido no .NET Core 3.0. Em vez de registrar rotas em controladores, ele registra diretamente as classes que implementam a lógica dos endpoints.
Cada classe que herda de Endpoint<TRequest, TResponse> ou Endpoint<TRequest> é automaticamente registrada como um endpoint na aplicação.
Durante a inicialização, o FastEndpoints escaneia o assembly e registra dinamicamente as classes que implementam a interface de endpoint.
Recursos utilizados pelo FastEndpoints:
Middleware Pipeline:
O FastEndpoints registra os endpoints na pipeline HTTP usando app.UseRouting() e app.UseEndpoints().
Reflection (Reflexão):
Ele usa reflection para encontrar todas as classes que herdam de Endpoint<> e registrá-las como endpoints HTTP.
Minimal APIs (Introduzidas no .NET 6):
Ele usa a API de rotas simplificada do Minimal APIs, mas oferece uma abordagem mais estruturada com base em classes.
♦
Assim, o FastEndoints não usa Controllers pois um controlador geralmente lida com várias ações (GET, POST, PUT, DELETE), o que pode dificultar a organização e manutenção do código.
Além disso, Controladores dependem de atributos para mapear rotas, enquanto o FastEndpoints elimina essa necessidade, permitindo declarar rotas diretamente nas classes de endpoint.
Desta forma ele usa classes separadas em vez de controladores pois cada classe de endpoint tem uma única responsabilidade (por exemplo, CreateProdutoEndpoint só lida com a criação de produtos). Com classes separadas, o código fica mais limpo e fácil de manter. Não há necessidade de lidar com controladores inchados.
As rotas são definidas diretamente dentro dos endpoints, tornando o mapeamento mais explícito e flexível e ainda possui suporte integrado para validações, resposta de erros padronizada e filtros de autenticação/autorização.
Tipos de endpoint no FastEndpoints
O FastEndpoints oferece 4 tipos de endpoints base, que você pode herdar de:
• Endpoint<TRequest>
Use este tipo se houver apenas um DTO de solicitação. No entanto, você pode enviar qualquer objeto ao cliente que possa ser serializado como uma resposta com essa sobrecarga genérica.
• Endpoint<TRequest,TResponse>
Use este tipo se você tiver DTOs de solicitação e resposta. O benefício dessa sobrecarga genérica é que você obtém acesso fortemente tipado às propriedades do DTO ao fazer testes de integração e validações.
• EndpointWithoutRequest
Use este tipo se não houver DTO de solicitação nem resposta. Você também pode enviar qualquer objeto serializável como resposta aqui.
• EndpointWithoutRequest<TResponse>
Use este tipo se não houver DTO de solicitação, mas houver um DTO de resposta.
♦
Também é possível definir endpoints com EmptyRequest e EmptyResponse, se necessário:
public classEndpoint : Endpoint<EmptyRequest,EmptyResponse> { }
Exemplo prático usando FastEndpoints
Neste nosso primeiro contato com o FastEndpoints vejamos como criar uma Web API para realizar o CRUD básico em Produto.
Crie um novo projeto no VS 2022 usando o template ASP.NET Core Web API com o nome ApiFastEndpointsCrud sem usar Controllers. Neste exemplo vou usar um banco de dados SQL Server.
A seguir inclua no projeto os seguintes pacotse nuget :
dotnet add package FastEndpoints
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
dotnet add package Microsoft.EntityFrameworkCore.Tools
Agora configure o FastEndpoints na classe Program:
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddOpenApi();
// Registrando o FastEndpoints
builder.Services.AddFastEndpoints();
var app = builder.Build();
// Ativando FastEndpoints
app.UseFastEndpoints();
...
Crie a pasta Entities no projeto e nesta pasta cria a classe Produto:
public class Produto
{
public int Id { get; set; }
public string Nome { get; set; } = string.Empty;
public decimal Preco { get; set; }
public int Estoque { get; set; }
}
Vamos criar uma pasta chamada Context no projeto e incluir nesta pasta a classe AppDbContext que herda de DbContext:
ppublic class AppDbContext : DbContext
{
public AppDbContext(DbContextOptions<AppDbContext> options) : base(options) { }
public DbSet<Produto> Produtos { get; set; }
}
Agora adicione na classe Program o código para registrar o serviço do contexto definindo o provedor do banco e obtendo a string de conexão:
...
builder.Services.AddDbContext<AppDbContext>(options =>
options.UseSqlServer(builder.Configuration.GetConnectionString("DefaultConnection")));
...
A seguir defina no arquivo appsettings.json a string de conexão usada para acessar o SQL Sever local:
...
"ConnectionStrings": {
"DefaultConnection": "Server=Macoratti\\SqlExpress;Database=FastEndpointsDB;Trusted_Connection=True;MultipleActiveResultSets=true;TrustServerCertificate=true;"
},
...
Criando os endpoints
Agora vamos criar as classes para cada Endpoint. Para isso vamos criar a pasta Produtos no projeto e nesta pasta vamos criar as seguintes classes:
📄 CriarProdutoEndpoint.cs – Para criar um produto (POST).
📄 CriarProdutoRequest.cs – DTO usado para fornecer os dados de entrada do produto
📄 ObterProdutosEndpoint.cs – Para listar todos os produtos (GET).
📄 ObterProdutoEndpoint.cs – Para obter um produto pelo seu id (GET).
📄 AtualizarProdutoEndpoint.cs – Para atualizar um produto (PUT).
📄 DeletarProdutoEndpoint.cs – Para deletar um produto por ID (DELETE).
📄 AtualizarProdutoRequest.cs – DTO usado para fornecer os dados de entrada.
📄 ObterProdutoIdRequest.cs – DTO usado para fornecer o Id do Produto
Essa estrutura mantém o código separado e organizado, facilitando a manutenção. Aseguir temos o código de cada classew
1- Listar todos os produtos
public class ObterProdutosEndpoint : EndpointWithoutRequest<List<Produto>>
{
private readonly AppDbContext _context;
public ObterProdutosEndpoint(AppDbContext context)
{
_context = context;
}
public override void Configure()
{
Verbs(Http.GET);
Routes("/produtos");
Get("/produtos");
AllowAnonymous();
}
public override async Task HandleAsync(CancellationToken ct)
{
var produtos = await _context.Produtos.ToListAsync(ct);
if (produtos.IsNullOrEmpty())
{
// Retorna 404 se não houver produtos.
await SendNotFoundAsync();
return;
}
await SendOkAsync(produtos); // Retorna 200 OK com a lista de produtos
// Ou, para melhor performance em alguns casos (dependendo do tamanho da lista):
// await SendAsync(produtos); // Envia diretamente a lista,
// sem serialização extra (pode precisar de configuração no Program.cs)
}
}
Vamos entender o código :
A classe herda de EndpointWithoutRequest<List<Produto>>, o que significa que:
EndpointWithoutRequest → Indica que não recebe nenhum dado na requisição (Body).
List<Produto> → O endpoint retorna uma lista de produtos.
O contexto é injetado via construtor (injeção de dependência), permitindo que o endpoint acesse os métodos para manipular dados.
O método Configure configura as propriedades do endopint:
| Método |
Descrição |
| Verbs() |
Define o verbo HTTP usado pelo endpoint (GET). |
| Routes() |
Define a rota do endpoint (/produtos). |
| AllowAnonymous |
Permite que o endpoint seja acessado sem autenticação. |
O método HandleAsync é o método principal do endpoint, que será chamado quando uma requisição for feita para /produtos.
__context.Produtos.ToListAsync(ct)→ Chama o método para buscar todos os produtos da base de dados.
SendOkAsync(produtos) → Envia a resposta ao cliente com a lista de produtos (status HTTP 200 OK).
Se o produto não for encontrado usando o método SendNotFoundAsync() para enviar um status code 404.
2- Criar um novo produto
public class CriarProdutoEndpoint : Endpoint<CriarProdutoRequest, Produto>
{
private readonly AppDbContext _context;
public CriarProdutoEndpoint(AppDbContext context)
{
_context = context;
}
public override void Configure()
{
Post("/produtos");
AllowAnonymous();
}
public override async Task
HandleAsync(CriarProdutoRequest req,
CancellationToken ct)
{
var produto = new Produto
{
Nome = req.Nome,
Preco = req.Preco,
Estoque = req.Estoque
};
_context.Produtos.Add(produto);
await _context.SaveChangesAsync(ct);
await SendCreatedAtAsync<CriarProdutoEndpoint>($"/produtos/{produto.Id}",
produto);
}
}
Esta classe usa o DTO CriarProdutoRequest para fornecer os dados do produto que será criado:
public class CriarProdutoRequest
{
public string Nome { get; set; } = string.Empty;
public decimal Preco { get; set; }
public int Estoque { get; set; }
}
3- Lista um produto pelo seu id
public class ObterProdutoEndpoint : Endpoint<ObterProdutoIdRequest>
{
private readonly AppDbContext _context;
public ObterProdutoEndpoint(AppDbContext context)
{
_context = context;
}
public override void Configure()
{
// {Id} deve corresponder à propriedade do DTO (case-sensitive)
Get("/produtos/{Id}");
AllowAnonymous();
}
public override async Task
HandleAsync(ObterProdutoIdRequest req,
CancellationToken ct)
{
// Acessa o ID através do DTO
var produto = await _context.Produtos.FindAsync(req.Id, ct);
if (produto == null)
{
await SendNotFoundAsync();
return;
}
await SendOkAsync(produto);
}
}
Esta classe usa o DTO ObterProdutoIdRequest para fornecer id do produto que será obtido.
public class ObterProdutoIdRequest
{
public int Id { get; set; }
}
4- Atualiza um produto
public class AtualizarProdutoEndpoint : Endpoint<AtualizarProdutoRequest>
{
private readonly AppDbContext _context;
public AtualizarProdutoEndpoint(AppDbContext context)
{
_context = context;
}
public override void Configure()
{
Put("/produtos/{id}");
AllowAnonymous();
}
public override async Task HandleAsync(AtualizarProdutoRequest req,
CancellationToken ct)
{
var produto = await _context.Produtos.FindAsync(req.Id, ct);
if (produto == null)
{
await SendNotFoundAsync();
return;
}
produto.Nome = req.Nome;
produto.Preco = req.Preco;
produto.Estoque = req.Estoque;
await _context.SaveChangesAsync(ct);
await SendOkAsync(produto);
}
}
Esta classe usa o DTO AtualizarProdutoIdRequest para fornecer o id do produto que será atualizado e os dados do produto que são herdados de CriarProdutoRequest:
public class AtualizarProdutoRequest : CriarProdutoRequest
{
public int Id { get; set; }
}
5- Excluir um produto
public class DeletarProdutoEndpoint : Endpoint<ObterProdutoIdRequest>
{
private readonly AppDbContext _context;
public DeletarProdutoEndpoint(AppDbContext context)
{
_context = context;
}
public override void Configure()
{
Delete("/produtos/{id}");
AllowAnonymous();
}
public override async Task HandleAsync(ObterProdutoIdRequest req,
CancellationToken ct)
{
var produto = await _context.Produtos.FindAsync(req.Id, ct);
if (produto == null)
{
await SendNotFoundAsync();
return;
}
_context.Produtos.Remove(produto);
await _context.SaveChangesAsync(ct);
await SendNoContentAsync(); // Retorna 204 No Content
}
}
Esta classe também usa o DTO ObterProdutoIdRequest para fornecer id do produto que será excluído.
public class ObterProdutoIdRequest
{
public int Id { get; set; }
}
Com isso temos os endpoints definidos e eles serão exibidos na interface do Swagger da seguinte forma:
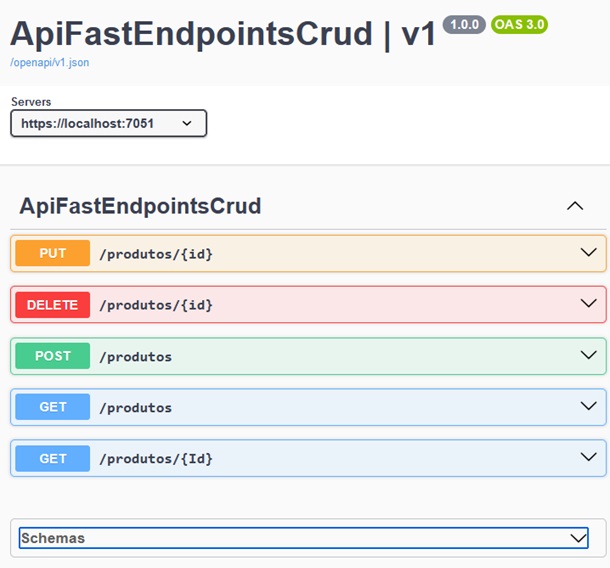
Para realizar os testes nestes endpoints de forma mais fácil podemos usar o Postman.
Pegue o projeto aqui:  ApiFastEndpointsCrud.zip
ApiFastEndpointsCrud.zip
E estamos conversados…