No tutorial de hoje eu vou lhe mostrar como construir uma aplicação web em Node.js para encurtar URLs, tipo o que o Bit.ly faz. Para esta tarefa, usaremos além do Node.js, o Express, o EJS, o Sequelize, o Bootstrap e o SQLite.
Como não quero ser repetitivo aqui, caso não conheça nada de alguma dessas tecnologias, recomendo que leia antes outros tutoriais, onde explico melhor cada uma delas.
- Express + EJS
- Sequelize + SQLite
Este tutorial não é para completos iniciantes, ele parte do pressuposto que você já saiba o básico de como fazer um CRUD com essa stack, além de entender um pouco de HTML+CSS.
Além disso, optei aqui por uma abordagem bem simples, porém bem feita. Certamente existem outras formas ainda mais profissionais de criar um encurtador de URL, apenas dei uma abordagem.
#1 – Setup do Projeto
Vamos começar criando o nosso projeto usando o meu fork do projeto express-generator para ganhar velocidade rapidamente. Seu uso é opcional, você pode criar a mesma estrutura toda na mão se quiser.
No código abaixo, eu mando instalar o generator e executá-lo para criar o projeto pra gente. Note que para rodar o npm globalmente você terá de executar o terminal como administrador.
npm install -g https://github.com/luiztools/express-generator.git
express --git url-shortener
Usei as flags -e para definir o EJS como nossa view-engine e –git para que o arquivo gitignore seja criado pra gente automaticamente.
Uma vez com a pasta criada e populada com o projeto de exemplo, acesse-a e mande instalar as dependências atuais e as novas que vamos precisar.
cd url-shortener
npm i
npm i dotenv sequelize sqlite3
Com as dependências instaladas, vamos ajustar o package.json para não apenas subir a nossa aplicação com os scripts como para deixá-la rodando e atualizando-se automaticamente conforme a gente for alterando os fontes da aplicação. Fazemos isso com o pacote nodemon.
"scripts": {
"start": "node -r dotenv/config ./bin/www",
"dev": "npx nodemon -r dotenv/config ./bin/www"
},
Acima eu deixei configurado dois scripts, o start, que é para ser usado em produção e o dev, que é para ser usado em desenvolvimento.
A diferença entre eles é o uso do nodemon, que em produção não é o que deve ser utilizado para manter a aplicação no ar. O mais comum é usarmos PM2 em produção, para esta finalidade.
Note que usei ‘npx nodemon’ ao invés de apenas nodemon, para que ele seja baixado a versão mais recente quando for utilizado.
Também note que fiz chamadas ao dotenv nos scripts também, isso fará com nossas variáveis de ambiente sejam carregadas antes mesmo da aplicação subir, para garantir que elas estejam ok quando precisarmos.
Já que falei em dotenv, vamos deixar criado o arquivo .env na raiz da nossa aplicação, precisaremos de apenas uma variável de ambiente nele, com a URL em que a aplicação estará rodando.
#.env
DOMAIN=http://localhost:3000/
Em produção, você irá alterar esse variável de acordo com o domínio que adquirir para o seu projeto (na Umbler você compra domínios a preço de custo). Usaremos mais tarde esta variável e ficará mais claro o porquê.
Agora rode a aplicação com npm run dev e ela deve subir tranquilamente em uma página inicial de exemplo, indicando que o setup do nosso projeto terminou.
#2 – Criando a tela inicial
Agora que temos o projeto minimamente configurado, vamos criar a tela inicial. Todas as views ficam na pasta views e a tela inicial é a index.ejs, vamos editá-la, a começar pelas dependências de front-end, onde usaremos o Bootstrap.
O head do seu index.ejs deve ficar assim.
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>
<%= title %>
</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/css/bootstrap.min.css" rel="stylesheet"
integrity="sha384-giJF6kkoqNQ00vy+HMDP7azOuL0xtbfIcaT9wjKHr8RbDVddVHyTfAAsrekwKmP1" crossorigin="anonymous">
<link rel='stylesheet' href='/stylesheets/style.css' />
</head>
As duas tags meta são exigência do Bootstrap, enquanto que a tag link é para justamente carregar o CSS dele para estilizarmos nossa página mais facilmente. Já a segunda tag link é para outra folha de estilo com alguns estilos adicionais que vamos criar.
Já o body do seu index.ejs deve ficar assim.
<body>
<div class="container">
<div class="header">
<img src="/images/web_server.png" alt="<%= title %>" class="icon" />
<h1>
<%= title %>
</h1>
<p>Seu novo encurtador de URL!</p>
</div>
<div class="content">
<form method="POST" action="/new">
<div class="mb-3 input-group">
<input placeholder="Digite a URL a ser encurtada" name="url" class="form-control" />
<div class="input-group-append">
<button class="btn btn-primary" type="submit">Encurtar</button>
</div>
</div>
</form>
</div>
</div>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.0.0-beta1/dist/js/bootstrap.bundle.min.js"
integrity="sha384-ygbV9kiqUc6oa4msXn9868pTtWMgiQaeYH7/t7LECLbyPA2x65Kgf80OJFdroafW"
crossorigin="anonymous"></script>
</body>
Aqui temos uma div container que é exigência de layout do Bootstrap, sendo que dentro eu estou usando uma imagem de ícone que baixei do site FindIcons.com que tem muita coisa bacana e gratuita. Salve-o na pasta public/images no seu projeto.
Criei no body um HTML Form que servirá para enviar os dados da URL original para o backend, a fim de encurtarmos ela. Falarei mais disso mais tarde.
No fim do body, temos uma tag script para carregar o JS do Bootstrap, outra dependência necessária para que ele funcione de maneira plena.
Vale salientar também o uso de server tags com <%= %> que são características do EJS e servem para imprimir variáveis do back-end em nosso front-end.
Esse body está usando algumas classes próprias, que não existem no Bootstrap e que devemos criar na nossa folha de estilos personalizada, que fica em public/stylesheets/style.css, abra esse arquivo, apague esse conteúdo e adicione o abaixo.
.header {
padding: 3rem;
text-align: center;
}
.icon {
height: 42px;
}
.content {
display: flex;
justify-content: center !important;
}
form {
flex: 0 0 80%;
padding: 2rem 2rem 1rem 2rem;
border: 1px solid #ccc;
border-radius: .25rem;
text-align: center;
}
Neste código CSS temos classes para o cabeçalho da página, para o ícone, para o conteúdo e para estilizar o próprio form dela.
O resultado você confere na imagem abaixo (o título eu já mostrarei na sequência como mudar).
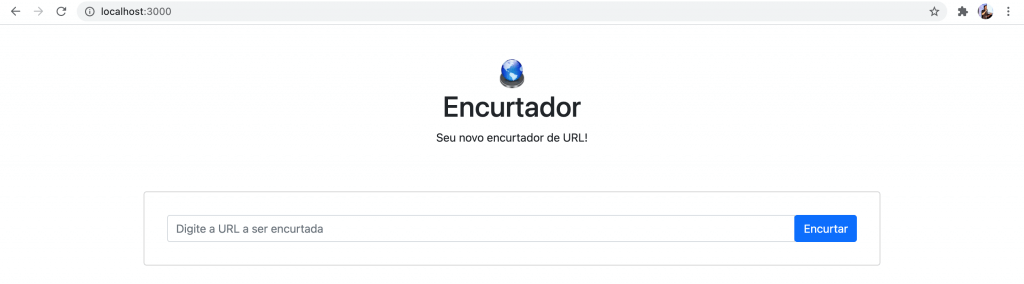
Se você digitar uma URL e mandar encurtar ela, vai dar um erro 404 no browser, pois o form está enviando para uma rota /new em nosso backend, que ainda não criamos. É o que iremos fazer na sequência.
#3 – Criando o backend
O express-generator já criou alguns módulos de roteamento para gente e é eles que vamos usar como base. Dentro de routes/index.js temos as rotas que atendem à nossa view index.ejs, então abra-o para editarmos ele a fim de adicionarmos os ajustes necessários, a começar editando a rota GET / para que ela devolva um título adequado à nossa aplicação.
/* GET home page. */
router.get('/', function (req, res, next) {
res.render('index', { title: 'Encurtador' });
});
Agora vamos criar uma função que vai gerar as urls encurtadas e que vai ser necessária para nossa aplicação fazer a sua principal funcionalidade. Coloque a função abaixo dentro da mesma index.js das rotas.
function generateCode() {
let text = '';
const possible = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
for (let i = 0; i < 5; i++)
text += possible.charAt(Math.floor(Math.random() * possible.length));
return text;
}
Na função acima, eu gero uma string com 5 caracteres alfanuméricos. Essa string será concatenada mais tarde com o domínio da aplicação e isso irá gerar a URL curta em si.
Agora, vamos criar a rota POST /new que será usada pelo HTML Form da index.ejs, sempre no mesmo arquivo de rotas index.js.
router.post('/new', async (req, res, next) => {
const url = req.body.url;
const code = generateCode();
res.send(`${process.env.DOMAIN}${code}`);
})
A rota acima é bem simples, ela recebe uma URL do corpo da requisição, gera o código randômico de url curta e devolve esse código concatenado com o domínio da aplicação, que deve estar configurado no seu arquivo .env, lembra? Isso vai nos ajudar a testar rapidamente e ver se os códigos estão sendo gerados corretamente e de maneira bem aleatória.
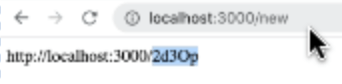
Nosso próximo passo envolve salvar esse código gerado, bem como a URL relacionada a ele, em um banco de dados, para que depois possamos fazer a funcionalidade de redirecionamento de também de estatísticas.
#4 – Criando o banco de dados
Vamos usar nesta aplicação o banco SQLite, que é um banco em arquivo super leve e fácil de usar, tipo o Access. Ele não exige qualquer instalação e ele roda junto do processo da sua aplicação, sem necessidade de especificar porta e coisas do tipo. Para aplicações de pequeno porte, como essa, ele vai atender bem.
O mais bacana é que, como vamos usar o ORM Sequelize, os detalhes do SQLite vão ficar completamente abstraído e caso você deseje utilizar outro banco SQL suportado pelo Sequelize no lugar do SQLite, basta instalar o pacote apropriado e mudar o dialect na configuração que faremos a seguir. Mais sobre Sequelize com outros bancos SQL nestes posts:
- Sequelize + MySQL
- Sequelize + PostgreSQL
Vamos criar um arquivo db.js na raiz do projeto para configurar a conexão com o nosso banco de dados.
const Sequelize = require('sequelize');
const sequelize = new Sequelize({
dialect: 'sqlite',
storage: './database.sqlite'
})
module.exports = sequelize;
Note que além da configuração dialect que diz ao Sequelize qual o banco de dados que ele vais e comunicar, definimos uma propriedade storage dizendo onde o arquivo do SQLite vai ser armazenado.
Agora, o próximo passo é configurarmos o modelo da entidade do banco de dados que vamos querer persistir e retornar os dados. Chamarei esse modelo de Link e ele deve ficar salvo em uma pasta models/link.js como seguinte conteúdo.
const Sequelize = require('sequelize');
const database = require('../db');
const Link = database.define('link', {
id: {
type: Sequelize.INTEGER,
autoIncrement: true,
allowNull: false,
primaryKey: true
},
code: {
type: Sequelize.STRING,
allowNull: false
},
url: {
type: Sequelize.STRING,
allowNull: false
},
hits: {
type: Sequelize.INTEGER,
allowNull: true,
defaultValue: 0
}
})
module.exports = Link;
Aqui, além de carregarmos as dependências do Sequelize e da nossa db.js de configuração, definimos as colunas da tabela link do nosso banco de dados, usando sintaxe em JS ao invés de SQL. Aqui eu disse que a tabela deve ter um id inteiro auto incremental, um code que é uma string, uma url que é outra string e a coluna hits servirá para contabilizarmos quantas vezes esse link foi acessado pela versão encurtada. Usaremos ele na parte de estatísticas mais tarde.
Agora temos de ajustar a inicialização da nossa aplicação para que ela carregue o banco de dados junto da aplicação e para que a tabela acima seja criada caso ela ainda não exista no banco, a fim de não termos erros durante a sua utilização posterior.
Faremos isso no arquivo bin/www onde acontece a subida inicial da aplicação, deixando-o como abaixo.
(async () => {
const database = require('../db');
const Link = require('../models/link');
await database.sync();
//restante fica igual
})();
Repare que carrego o arquivo de configuração e o arquivo de modelo, mesmo que eu não vá usar este segundo, isso é necessário. Logo depois uso a função sync do database, para garantir que as tabelas necessárias existirão no nosso banco.
Como eu usei a palavra reservada await para “aguardar” pelo retorno do database.sync, tive de colocar todo o conteúdo do bin/www em um IIFE async.
Ao rodar novamente a sua aplicação agora, a tabela links será criada e inclusive isso será avisado no console da sua aplicação, em uma mensagem parecida com a abaixo.
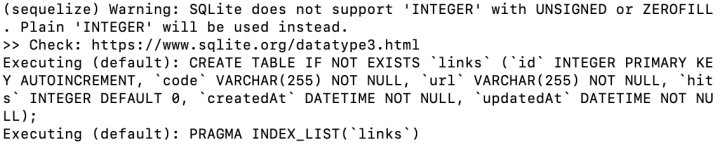
Se tudo deu certo, você terá um arquivo .sqlite na raiz da sua aplicação, que inclusive pode ser aberto pela aplicação SQLite Browser.
E para finalizar esta seção, volte ao routes/index.js e modifique a rota de POST /new para que agora salve o novo link no banco de dados usando o modelo que criamos e que depois disso redirecione para a view de estatísticas, que ainda não criamos.
router.post('/new', async (req, res, next) => {
const url = req.body.url;
const code = generateCode();
const resultado = await Link.create({
url,
code
})
res.render('stats', resultado.dataValues);
})
Com o código acima, você já deve conseguir ver os links sendo salvos no banco, mas deve dar error 404 no browser pela inexistência da view stats, que mandamos renderizar ao final do processo acima.
#5 – Criando a view de estatísticas
Agora vá na sua pasta views e crie uma stats.ejs, com o conteúdo abaixo no topo do HTML.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>
Encurtador
</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.5/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-SgOJa3DmI69IUzQ2PVdRZhwQ+dy64/BUtbMJw1MZ8t5HZApcHrRKUc4W0kG879m7" crossorigin="anonymous">
<link rel='stylesheet' href='/stylesheets/style.css' />
</head>
Aqui não há nenhuma novidade em relação à view index.ejs e se você quiser evitar repetição de código, pode dar uma estudada em partial-views.
Indo para o body do HTML, temos.
<body>
<div class="container">
<div class="header">
<img src="/images/web_server.png" alt="Encurtador" class="icon" />
<h1>
Encurtador
</h1>
<p>Estatísticas de acesso</p>
</div>
<div class="stats">
<p>
<b>
<%= process.env.DOMAIN %><%= code %>
</b>
</p>
<p>
Redireciona para:<br />
<%= url %>
</p>
<div class="statsRow">
<div class="statsBox">
<b>
<%= hits %>
</b>
<p>Visitas</p>
</div>
<div class="statsBox">
<b>
<%= updatedAt %>
</b>
<p>
Última Visita
</p>
</div>
</div>
<a href="/" class="btn btn-primary">Encurtar nova URL</a>
</div>
</div>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.5/dist/js/bootstrap.bundle.min.js" integrity="sha384-k6d4wzSIapyDyv1kpU366/PK5hCdSbCRGRCMv+eplOQJWyd1fbcAu9OCUj5zNLiq" crossorigin="anonymous"></script>
</body>
</html>
Nesta tela, nós apresentaremos o link que acabou de ser gerado (encurtado), o link original e estatísticas de quantos acessos ele já teve (campo hits da tabela links) e quando foi o último acesso (tem um campo updatedAt que o Sequelize gera automaticamente pra gente, usaremos ele).
Para essa tela ficar com uma boa aparência, serão necessárias algumas classes CSS novas, que devem ser adicionadas no public/stylesheets/style.css, no final dele.
.stats{
text-align: center;
}
.statsBox{
flex: 0 0 25%;
padding: 2rem;
border: 1px solid #ccc;
border-radius: .25rem;
text-align: center;
margin: .5rem;
}
.statsRow{
display: flex;
justify-content: center !important;
}
Agora ao testar novamente a aplicação, você pode encurtar URLs corretamente, no entanto o redirecionamento delas ainda não irá funcionar e consequentemente as estatísticas em si, também não. Mas já está ficando bem bacana.
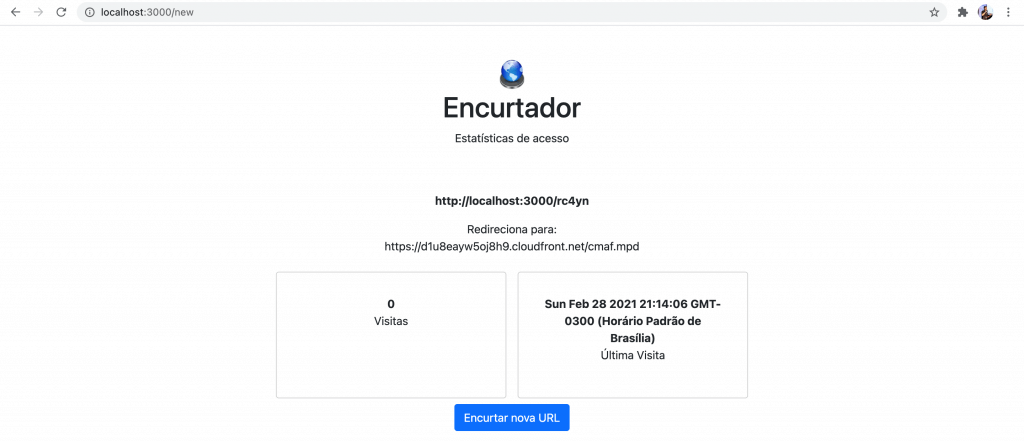
#6 – Fazendo funcionar a URL curta
O nosso próximo desafio do nosso encurtador de URL é que quando alguém acesse a URL curta, que o acesso seja contabilizado e a pessoa seja redirecionada para a URL original.
Para isso, vamos em routes/index.js e vamos criar uma rota para tratar os acessos nas URLs encurtadas. Essa rota deve ser a primeira do arquivo.
router.get('/:code', async (req, res, next) => {
const code = req.params.code;
const resultado = await Link.findOne({ where: { code } });
if (!resultado) return res.sendStatus(404);
resultado.hits++;
await resultado.save();
res.redirect(resultado.url);
})
Aqui nós temos uma rota GET /code onde code é um código qualquer que virá na url, representando a versão encurtada da URL original. Com esse código, nós vamos no banco de dados através da função findOne, pegamos o link, incrementamos e atualizamos esse link e depois redirecionamos o usuário para a URL original.
Apesar de todos esses passos no backend, para o usuário vai ser instantâneo, como se a URL curta tivesse levado ele para o site original em um único passo.
E para finalizar, agora que temos o funcionamento principal 100% e os hits sendo contabilizados, é hora de criarmos uma última rota, para que o dono do link possa acessar as estatísticas do mesmo, através de uma rota GET /code/stats. Essa rota deve ser a primeira do arquivo, antes mesmo da rota que criamos anteriormente.
router.get('/:code/stats', async (req, res, next) => {
const code = req.params.code;
const resultado = await Link.findOne({ where: { code } });
if (!resultado) return res.sendStatus(404);
res.render('stats', resultado.dataValues);
})
Aqui a ideia é muito próxima da rota anterior, mas nessa não incrementamos os hits e ao invés de redirecionar o usuário, renderizamos a view stats passando os dados do banco pra ela.
Se você testar a aplicação agora, encurte uma URL, acesse ela algumas vezes através da versão encurtada e depois finalize os testes acessando a URL curta mas com /stats ao final, você verá algo semelhante como abaixo.

E com isso finalizamos a nossa aplicação!
Para hospedar esta aplicação, você pode usar a AWS ou a Heroku, só para citar dois exemplos que possuem tutoriais aqui no blog. Não esqueça de mudar o seu .env para o domínio que for usar para este projeto.
Se quiser criar uma área logada, para que usuários possam ver os links que eles criaram, você pode adaptar o tutorial de Passport e é claro criar mais uma tabela de usuários no banco de dados.
Enfim, tem muita coisa bacana que você pode fazer para incrementar este projeto, então fique a vontade para seguir trabalhando nele!