Se você vê beleza em códigos, cita Senhor dos Anéis em reuniões e coleciona mais Funko Pop do que talheres, 25 de maio é o seu dia: o glorioso Dia do Orgulho Nerd. Também conhecido como Dia da Toalha, essa data é um hino à cultura geek — com muito carisma, referências e, claro, memes de qualidade duvidosa.
Dia do Orgulho Nerd – Por que o dia 25 de maio?
A escolha da data não foi aleatória nem tirada de uma planilha. Em 25 de maio de 1977, o mundo conheceu Star Wars – Episódio IV: Uma Nova Esperança. O filme dirigido por George Lucas não só revolucionou os efeitos especiais como fundou uma nova religião não-oficial: o “Jediísmo” (Fonte: IMDb – Star Wars Release Date)
Desde então, esse dia virou símbolo da virada cultural em que o que era “coisa de nerd” virou… bom, cultura pop.
E a toalha?
Também no dia 25, mas por outro motivo, fãs de O Guia do Mochileiro das Galáxias homenageiam Douglas Adams, autor da obra que fez a gente entender que uma toalha é o item mais importante que um viajante intergaláctico pode ter. O Dia da Toalha foi criado por fãs dois anos após a morte de Adams, em 2001.
Se você cruzar com alguém de óculos, camiseta preta e uma toalha pendurada no pescoço, não estranhe. Ele só está sendo 42% mais legal que você hoje. (Sim, 42. Nerds entenderão.)
Ser nerd virou hype?
Antigamente, ser nerd era quase um castigo social. Hoje? É business.
Streaming, jogos, quadrinhos, programação e ciência nunca estiveram tão em alta. Segundo a Statista, o mercado geek global movimentou mais de US$ 300 bilhões em 2023 — e crescendo!
As empresas tech vivem caçando devs que adoram ficção científica. Eventos como Comic-Con e BGS atraem milhões. Ou seja: o mundo é dos nerds. Só não viu quem ainda tá na Matrix.
Nerd é quem não tem medo de ser curioso
Seja você fã de anime, de física quântica ou de D&D, ser nerd é, no fim, abraçar a curiosidade com orgulho. É mergulhar em universos paralelos, discutir teorias improváveis e amar o que se faz — mesmo que ninguém mais entenda.
Com orgulho e referência!
Hoje, use seu anel do Lanterna Verde, sua blusa do Goku ou a toalha do mochileiro. Fale em código binário se quiser. Esse é o dia pra ser quem você é, sem medo de ser spoiler.
Feliz Dia do Orgulho Nerd, e que a Força esteja com você. 🖖
A Inteligência Artificial (IA) não para de avançar, uma das provas mais recentes disso é o “vibe coding”. Esse conceito representa uma verdadeira transformação na forma como devs e profissionais de outros setores interagem com o código: agora é possível criar projetos de software em ritmo de conversa, usando linguagem natural.
Vibe coding
O termo explodiu em fevereiro de 2025, graças a uma publicação de Andrej Karpathy, referência no setor de tecnologia, com passagens pela Tesla e OpenAI. No post, ele descreveu essa nova maneira de programar, em que comandos de texto ou de voz podem ser usados para escrever códigos, reduzindo a necessidade de digitação manual e repetitiva.
A ideia dessa nova abordagem é tornar a IA uma parceira tão eficiente que o desenvolvedor pode concentrar sua atenção no resultado, em vez de se prender à escrita do código. É uma maneira mais intuitiva de programar, que acelera o processo e libera o profissional para focar na análise de erros e na tomada de decisões estratégicas.
Para quem não é da área técnica, o vibe coding também funciona como um assistente. Usuários conseguem tirar ideias do papel, sem depender exclusivamente do retorno do time de tecnologia, por exemplo.
Como funciona na prática
No vibe coding, a principal “linguagem” utilizada é a natural, como inglês ou português. O usuário descreve o que precisa, e as IAs como ChatGPT, Gemini, Claude ou DeepSeek transformam essas instruções em código com alta precisão. Ferramentas como Cursor, GitHub Copilot e Windsurf já integram esses modelos em seus fluxos de desenvolvimento, tornando a experiência ainda mais fluida e colaborativa.
Durante o uso, é importante entender que o papel do dev se transforma: ele assume a função de “diretor” e “revisor”, enquanto a IA atua como parceira de programação. Ela gera códigos reais em linguagens de programação amplamente utilizadas, como Python, JavaScript, entre outras.
Por isso, quem tem pouca familiaridade com a codificação deve ficar atento para não confundir essa abordagem com o no-code e o low-code. Diferentemente do vibe coding, esses conceitos priorizam interfaces visuais, justamente para minimizar o contato direto com a programação.
E os próximos passos?
Com a velocidade que as IAs estão evoluindo, o vibe coding tem potencial para ser mais do que um “hype”. Apesar disso, o seu impacto traz dois lados.
Em um deles, a inovação pode ser uma porta de entrada para iniciantes, quebrando a barreira intimidadora da sintaxe e permitindo resultados rápidos. Do outro, há o risco de dependência excessiva da IA, o que pode comprometer o domínio dos fundamentos da programação, essenciais para criar aplicações complexas e otimizar a performance, além de potencialmente causar problemas de segurança, caso a pessoa desenvolvedora não saiba encontrá-los.
Por enquanto, o vibe coding tem sido mais recomendado para a criação de protótipos, uma vez que o desenvolvimento de um produto final pode demandar mais rigor, estrutura e habilidades avançadas de programação.
Por isso, é fundamental adotar a ferramenta com um olhar estratégico: aprender com ela, sem abrir mão do estudo contínuo e da prática consciente. Usar a IA como aliada, sem se apoiar totalmente nela, é o caminho para ganhar eficiência sem perder profundidade técnica.
Além disso, será cada vez mais importante acompanhar os debates sobre qualidade, segurança e governança do código gerado. Temas que certamente ganharão força nos próximos anos. E você, qual abordagem prefere utilizar em suas codificações?
Todo engenheiro de dados (Data Engineer) e desenvolvedor de software (Software Engineer) está ou vai estar muito “Harmonizado” e na minha visão deve estar engajado com o desenvolvimento de soluções de AI. Ok, tudo bem, neste artigo vou mirar mais no meu publico que são os Data Analytics Engineer, Data Architech, Data Engineer, DBRE etc.. mas você, desenvolvedor, vai precisar saber disso também. Mas, por que, então, vou escrever esse artigo mais para o publico de Data? Bom por que aqui no Brasil, o Databricks é massivamente utilizado para questões de Data e não desenvolvimento de software. Contudo, todos de tecnologia devem saber o conceito de RAG e, neste artigo, vou ensinar como fazer um fluxo de RAG completo utilizando 100% o Databricks e todos os recursos que ele já oferece para tornar isso possível.
Vamos nessa introdução clássica para conseguir aprofundar no tema: o que é RAG?
O que é RAG?
RAG é uma arquitetura que combina um componente de recuperação de informação com um modelo generativo. Quando uma pergunta é feita, o sistema primeiro busca documentos ou trechos de texto relevantes de uma base de conhecimento. Em seguida, esses documentos recuperados são fornecidos como contexto adicional ao LLM, que então gera uma resposta mais informada e precisa.
Resumindo, ele alimenta uma AI com informações da sua empresa, o que digamos que é uma coisa MUITO NECESSARIA.
Por que Databricks para RAG?
A Databricks Data Intelligence Platform oferece diversas vantagens para a construção de sistemas RAG:
Unified Data Lakehouse: Armazene, processe e gerencie todos os tipos de dados (estruturados, semiestruturados e não estruturados) em um único local com Delta Lake.
Processamento Escalável: Utilize Apache Spark para processamento de dados em larga escala, essencial para lidar com grandes volumes de texto.
Gerenciamento de Modelos: MLflow e Databricks Model Serving simplificam o rastreamento, versionamento, implantação e monitoramento de modelos de embedding e LLMs.
Vector Search (Busca Vetorial): Databricks oferece soluções nativas para busca vetorial, permitindo a criação e consulta eficiente de índices de embeddings.
Unity Catalog: Governança de dados, linhagem e descoberta de ativos em todo o seu pipeline de RAG.
Workflows: Orquestre pipelines complexos de RAG de forma programática.
Notebooks e Colaboração: Ambiente interativo para desenvolvimento, experimentação e colaboração.
Model serving Endpoint:Registra seu modelo e provisiona como uma API com varias pequenas features como monitoria, threshold, Guardrails entre outras funcionalidades.
Etapas para Construir um Pipeline RAG no Databricks
Vamos detalhar as etapas envolvidas na criação de um sistema RAG no Databricks:
Bom, aqui eu espero que todos já saibam montar delta tables, tipos de arquitetura de dados, medalion etc… certo? Então, você tem lá várias tabelas gold que representam por exemplo, um sistema de chamados, algumas são comentários dos chamados, outras somente o que é o chamado, etc..
Se você receber o desafio de construir uma AI que compreenda bem melhor os tipos e o que e como estão os chamados abertos para sua empresa, como devemos começar?
Primeiramente, uma Gold no estilo OBT – One big Table, que tenha todo o sistema de chamado em uma única tabela. Legal, a partir disso, é necessário fazer algumas analises exploratórias, principalmente nas colunas valiosas para sua AI, que são: titulo do chamado, tipo do chamado, data de abertura, data de resolução e comentários (iteração entre o solicitante e o atendente).
Mas já não é uma Gold, por quê preciso fazer essa análise como uma espécie de limpeza de dados? Pois é, meu caro, AI não chegou a passos curtos…. Digo isso para empresas que já têm seu Datalake, Data warehouse, Data hub, enfim, para quem está nascendo, já pensa em AI. Como eu li recentemente sobre o Nubank “Somos uma empresa AI-First“.
Então, vamos lá entender os dados para ficar bonitinho para nosso banco vetorial.
Análises Exploratórias (EDA):
Compreensão da Estrutura dos Dados:
Identifique os campos relevantes: Título do chamado, descrição, comentários, status (aberto, em andamento, resolvido, fechado), data de criação, data de resolução, prioridade, categoria, tags, logs de sistema, anexos.
Analise a distribuição de chamados por status, prioridade, categoria.
Verifique a completude dos campos: Quais campos possuem muitos valores ausentes
Análise do Conteúdo Textual:
Tamanho do Texto: Verifique a distribuição do comprimento das descrições e comentários. Isso ajudará a definir estratégias de chunking.
Linguagem: Identifique os idiomas presentes nos chamados. Se houver múltiplos idiomas, pode ser necessário traduzir ou usar modelos de embedding multilíngues.
Qualidade do Texto: Procure por erros de digitação, abreviações comuns, jargões específicos do domínio.
Presença de Formatação Especial: Tickets frequentemente contêm HTML, Markdown, snippets de código, stack traces ou URLs. Decida como tratar esses elementos (remover, extrair, converter para texto puro).
Identificação de PII (Informações de Identificação Pessoal): Busque por nomes, emails, telefones, CPFs, etc., que precisam ser anonimizados ou removidos.
Análise Temporal:
Como o volume de chamados varia ao longo do tempo?
Existem padrões sazonais ou tendências?
Relações entre Chamados:
Identifique chamados duplicados ou relacionados.
Analise o fluxo de resolução: Quais são as etapas comuns?
Limpeza de Dados:
Remoção/Anonimização de PII: Utilize técnicas como regex, bibliotecas de detecção de PII (ex: presidio) ou serviços cognitivos para identificar e mascarar/remover dados sensíveis.
Tratamento de HTML/Markdown: Use bibliotecas como BeautifulSoup (Python) para remover tags HTML e extrair o texto puro, ou converter Markdown para texto.
Confesso que muitos não consigo tirar conclusões, mas sigo a receita. Feito isso, agora seus dados estão prontos para os termos que podem ser novos para você, como: chunking, embeding, vetorização. Mas antes disso é importante você fazer uma última coisa com os dados dessa tabela, unificar as informações importantes em uma única coluna, que normalmente chamamos de content. Ela, em nosso caso, terá na ordem titulo do chamado, descrição do chamado e depois toda iteração do chamado, identificando o que foi uma pergunta e o que foi uma resposta, ou seja, solicitante e atendente.
Agora, sim, vamos para a codificação:
1. Realizar o chunk da coluna content:
Vou explicar rapidinho o que é chunk: “chunk” se refere a um segmento de texto menor e mais gerenciável, extraído de um documento maior, para facilitar a busca e recuperação de informações relevantes. Quer saber mais, vai no perplexity.ai e busca (google não, virou Kodak).
Como fazer o Chunk? Bom, existe um framework, que você vai ouvir falar muito, chamado langchain, que já tem diversos tipos de chunks prontinhos para realizarmos. Neste caso, o código será:
Imagem gerada da minha função com langchain para Chunk
Bacana, não? E o mais bacana é que eu só escrevo bacana, mas não falo bacana, enfim. O que estamos fazendo aí, para quem não entendeu, além da enxurrada de comentários:
Validação da Entrada: Primeiro, ele verifica se o texto fornecido (texto_concatenado) é válido (não é nulo, vazio ou de um tipo diferente de string). Se não for, retorna uma lista vazia.
Remoção de Duplicações Iniciais: O código suspeita que o texto de entrada pode ter seções inteiras duplicadas, separadas por ” | “. Ele divide o texto por esse separador. Para cada parte, ele calcula um “hash” (uma espécie de impressão digital única do texto) usando o algoritmo MD5. Ele mantém apenas as partes com hashes únicos, eliminando assim as duplicações em nível de seção. O texto é reconstruído sem essas duplicações.
Divisão Semântica (Chunking): Ele utiliza a biblioteca langchain com RecursiveCharacterTextSplitter. Esta ferramenta é projetada para quebrar textos grandes em pedaços menores, tentando manter o significado. Uma lista de separadores é definida (como “Pergunta:”, “Resposta:”, ” | “, etc.). O RecursiveCharacterTextSplitter tentará quebrar o texto nesses pontos prioritariamente. Parâmetros como chunk_size (tamanho máximo de cada pedaço) e chunk_overlap (quanto de texto se sobrepõe entre pedaços consecutivos para manter o contexto) são configurados. O texto (já sem as duplicações de seção) é então dividido nesses chunks.
Processamento e Filtragem dos Chunks: Cada chunk gerado passa por um processo de limpeza e validação: Espaços em branco no início e no fim são removidos. Chunks vazios são descartados. Chunks muito pequenos (menos de 20 caracteres) são ignorados, a menos que contenham termos chave como “Pergunta:”, “Resposta:” ou “Titulo”, indicando que podem ser importantes apesar do tamanho. Remoção de Duplicações em Nível de Chunk: Semelhante à etapa 2, um hash MD5 é calculado para cada chunk. Se um chunk com o mesmo conteúdo (mesmo hash) já foi processado, ele é descartado para evitar redundância na saída final.
Retorno: A função retorna uma lista de chunks_processados, que são os pedaços de texto finais, limpos, sem duplicações e divididos semanticamente.
Em resumo, o código é uma ferramenta de pré-processamento de texto que limpa e organiza comentários concatenados, tornando-os mais fáceis de serem processados por outras ferramentas ou modelos de linguagem, ao dividi-los em unidades menores e relevantes e removendo repetições.
E agora com o resultado adivinha? Você vai criar uma nova coluna chamada chunk_content, ou chunk_text enfim. E por que fizemos o chunk? para seguirmos para o mais mirabolante que eu vou explicar bem pouco que não estudei afundo o embedding. Ah mas entender o embedding é simples, sim é simples o tipo mais comum sem se aprofundar no seus parametros ou nos outros tipos de embedding como
Dense Embeddings
Sparse Embeddings
Hybrid Embeddings/Search
Enfim, vamos no arroz com feijão que é bom e todo Brasileiro sabe disso. Portanto no databricks como posso fazer o embedding? Bom tem 2 formas:
1.Usar modelos open-source do Hugging Face (via transformers ou MLflow) ou modelos proprietários.
2.O Databricks Model Serving hospedar diversos modelos para embedding e conversação (Chat).
Como hoje estou com preguiça vamos de Model Serving da databricks para facilitar a vida. E para ser mais fã da databricks vou escolher um modelo LLM de embedding que tem o nome databricks nele: databricks-bge-large-en. Agora como é feito o embedding, bom lembra que falei que estou com preguiça hoje? pois bem eu criei uma função que já retorna os embedding a partir de uma lista que neste caso nós passamos a coluna de chunk lembra?
Função para realizar o Embedding da coluna Chu
E agora só fazer o mesmo que fizemos para criar a coluna de chunk mas dessa vez essa coluna deve ser OBRIGATÓRIAMENTE chamada de embedding:
Claro que no código acima eu já suponho né que sua variável df seja sua tabela completa com o chunk.
Ok, recapitulando o que foi feito até aqui:
Analise exploratória dos dados.
Limpeza e normalização.
Junção de colunas importantes em uma unica coluna.
Criamos a coluna de chunk com base na coluna unica que chamamos de content.
Criamos a coluna de embedding com base na coluna de chunk chamada de chunk_text.
Agora estamos prontos para uma das facilidades do databricks que é tornar nossa tabela delta contendo os embeddings uma tabela com índice vetorial. Você pode configurar o tipo de índice (direto ou Delta Sync) e a métrica de similaridade (ex: cosseno, produto escalar).
Primeiramente você precisa habilitar o Change Data Feed da sua tabela:
Este código verifica se esta habilitado a tabela, do contrario habilita a propriedade, agora precisamos criar um Vector Search, registrar o index da sua tabela e um endpoint para receber as predições. Vamos entender então mais sobre o Vector Search:
O Databricks oferece o Vector Search, uma solução de banco de dados vetorial sem servidor e de baixa latência. Ele se integra perfeitamente com o Unity Catalog e o Model Serving.
Criação do Endpoint: Crie um endpoint do Vector Search através da UI do Databricks ou da API.
Criação do Índice: Crie um índice vetorial a partir da sua tabela Delta contendo os embeddings. Você pode configurar o tipo de índice (direto ou Delta Sync) e a métrica de similaridade (ex: cosseno, produto escalar).
A Databricks oferece dois modos principais de indexação: o Delta Sync Index, que sincroniza automaticamente com uma tabela Delta e pode calcular embeddings ou usar embeddings pré-existentes, e o Direct Vector Access Index, que permite inserção e atualização manual de vetores e metadados via API ou SDK. Por baixo dos panos ouvi dizer que é pgvector (https://github.com/pgvector/pgvector), ou seja um PostgreSQL Vetorial.
Ok, agora vamos criar nosso Vector Search, o index, referenciar nossa tabela e o endpoint via python, tem como fazer via interface? sim tem, mas ai ficar tirando print e colocando aqui eu iria demorar muito e via código é mais rápido não é mesmo.
Grande o código não, mas ele já faz varias validações esta como Classe para incluir mais métodos como atualizar o index, realizar buscas etc.. Explicando melhor o código:
Este código define uma classe Python chamada AiVectorSearch, projetada para gerenciar um processo de ETL (Extração, Transformação e Carga) focado na criação e sincronização de um índice de pesquisa vetorial. A pesquisa vetorial é comumente usada em aplicações de IA para encontrar itens semelhantes com base em embeddings (representações vetoriais de dados).
A seguir, uma análise hierárquica da classe e seus métodos:
1.Classe: AiVectorSearch Esta é a classe principal que encapsula toda a lógica para o processo de ETL da pesquisa vetorial.
1.1. Método Construtor: __init__(self, …) Objetivo: Inicializar uma nova instância da classe AISVectorSearchETL. Parâmetros Principais: source_table_name: Nome da tabela de origem dos dados. source_table_type: Tipo da tabela de origem (ex: “TABLE”, “VIEW”). vector_search_endpoint_name: Nome do endpoint do serviço de pesquisa vetorial. embedding_column: Nome da coluna que contém os embeddings vetoriais. text_column: Nome da coluna que contém o texto original (opcional, mas útil para referência). primary_key: Nome da coluna da chave primária na tabela de origem. id_column: Nome da coluna que será usada como ID no índice vetorial. Ações: Armazena os parâmetros recebidos como atributos da instância (ex: self.source_table_name). Inicializa outros atributos internos, como self.ws (provavelmente um cliente do workspace, ex: Databricks), self.vs_endpoint, self.index_name, self.index_info, self.pipeline_type. Define o nome do índice (self.index_name) combinando o nome do endpoint e o nome da tabela de origem. Define o tipo de pipeline (self.pipeline_type), que parece ser “DELTA_SYNC” com base no código.
1.2. Método Privado: _get_vs_endpoint(self) Objetivo: Obter os detalhes do endpoint da pesquisa vetorial especificado. Ações: Utiliza self.ws.vector_search.get_endpoint() para buscar as informações do endpoint. Armazena o resultado em self.vs_endpoint. Imprime uma mensagem indicando se o endpoint foi encontrado ou não.
1.3. Método Privado: _get_index_info(self) Objetivo: Obter informações sobre o índice de pesquisa vetorial, como seu status e tipo. Ações: Chama self._get_vs_endpoint() para garantir que as informações do endpoint estejam disponíveis. Tenta obter o índice usando self.ws.vector_search.get_index(endpoint_name=self.vector_search_endpoint_name, index_name=self.index_name). Se o índice existir: Armazena as informações do índice em self.index_info. Imprime o nome, tipo e status do índice. Se o índice não existir (captura uma exceção, provavelmente HttpError com status 404): Define self.index_info como None. Imprime uma mensagem indicando que o índice não foi encontrado.
1.4. Método Privado: _create_index_if_not_exists(self) Objetivo: Criar o índice de pesquisa vetorial se ele ainda não existir. Ações: Chama self._get_index_info() para verificar o estado atual do índice. Se self.index_info for None (índice não existe): Imprime uma mensagem indicando que o índice será criado. Chama self.ws.vector_search.create_delta_sync_index(…) para criar um novo índice de sincronização Delta. Parâmetros para criação: endpoint_name: Nome do endpoint. index_name: Nome do índice. source_table_name: Tabela de origem dos dados. pipeline_type: Tipo de pipeline (ex: “DELTA_SYNC”). primary_key: Chave primária da tabela de origem. embedding_vector_column (ou similar, o nome exato pode variar na imagem): Coluna de embedding. embedding_dimension (ou similar): Dimensão dos vetores de embedding. text_column (ou similar, se aplicável): Coluna de texto. Atualiza self.index_info chamando self._get_index_info() novamente. Se o índice já existir: Imprime uma mensagem indicando que o índice já existe e seu status.
1.5. Método Privado: _wait_for_index_online(self) Objetivo: Pausar a execução até que o índice de pesquisa vetorial esteja no estado “ONLINE” e pronto para uso. Ações: Chama self._get_index_info() para obter o status mais recente do índice. Entra em um loop while que continua enquanto o status do índice (self.index_info.status.detailed_state) não for “ONLINE”. Dentro do loop: Imprime o status atual do índice. Aguarda por um período fixo (ex: 30 segundos) usando time.sleep(30). Atualiza as informações do índice chamando self._get_index_info() novamente. Quando o loop terminar (índice está “ONLINE”): Imprime uma mensagem confirmando que o índice está online.
1.6. Método Privado: _sync_data(self) Objetivo: Orquestrar o processo de criação (se necessário), espera e sincronização de dados para o índice. Ações: Chama self._create_index_if_not_exists() para garantir que o índice exista. Chama self._wait_for_index_online() para garantir que o índice esteja pronto. Verifica se o tipo de índice é “DELTA_SYNC”. Se for, e se houver um self.index_info válido, ele tenta sincronizar os dados. A imagem mostra idx.sync(), onde idx seria self.index_info ou um objeto de índice obtido a partir dele. Isso sugere que o objeto index_info (ou o objeto retornado por get_index) tem um método sync(). Imprime mensagens sobre o início e a conclusão da sincronização. Se o tipo de índice não for “DELTA_SYNC” ou se self.index_info for inválido, imprime uma mensagem apropriada.
1.7. Método Público: run(self) Objetivo: Ponto de entrada principal para executar todo o processo de ETL da pesquisa vetorial. Ações: Imprime uma mensagem indicando o início do processo de ETL. Chama o método self._sync_data() para realizar a sincronização. Imprime uma mensagem indicando a conclusão do processo de ETL.
Resumo da Hierarquia e Fluxo:
Um objeto AiVectorSearch é instanciado com as configurações necessárias.
O método run() é chamado para iniciar o processo.
run() chama _sync_data().
_sync_data() primeiro chama _create_index_if_not_exists(): _create_index_if_not_exists() chama _get_index_info() para verificar se o índice existe. _get_index_info() chama _get_vs_endpoint() para obter detalhes do endpoint. Se o índice não existir, _create_index_if_not_exists() o cria.
_sync_data() então chama _wait_for_index_online(): _wait_for_index_online() chama repetidamente _get_index_info() para monitorar o status do índice até que ele esteja online.
Finalmente, _sync_data() (se o índice for do tipo correto e estiver online) executa a operação de sincronização de dados (ex: idx.sync()).
Agora com toda parte do Vector Search realizada você terá visualmente no databricks:
Repare que agora você tem um banco de dados vetorial criado, com 1 index que é da sua tabela e o creator que ficara o seu e-mail.
The end: Registrando seu modelo com esse fluxo de RAG como uma API através do Model Serving endpoint da Databricks.
Se você se aventurar e ir na seção de Serving no databricks verá vários modelos da databricks que são de modelos proprietários e grande parte opensource:
O que queremos é registrar seu modelo como um modelo Chat e que apareça aqui como disponível para uso como API para receber perguntas passar pelo banco vetorial, receber mais contexto, passar pelo pré-prompt e por ultimo enviar para a LLM de chat que vai nos devolver a resposta.
Primeiro ponto é criar o código que vai realizar toda essa orquestração que neste caso eu denominei de RagChatModel onde ela é responsável por fazer busca vetoriais, obter retorno do LLM de chat, realizar o processo de embedding da pergunta do usuário, definir temperatura do modelo do chat que basicamente define o quanto ele pode ser criativo ou não, qual é meu endpoint do vector search, qual o LLM de chat, que neste caso vamos utilizar o databricks-meta-llama-3-1-8b-instruct e qual a tabela de origem.
Soltar a bomba:
Legal e como registro essa classe no Model Serving Endpoint no databricks?
A saída será mais ou menos desta forma ao rodar no seu notebook Databricks:
Agora sim se olharmos no Serving endpoints veremos nosso modelo RAG com API registrado e gerenciado pela Databricks:
E por ultimo se você estiver construindo com mlflow e utilizara classe mlflow.pyfunc.ChatModel
Você testar no Playground do databricks:
Conclusão: o que criamos se resume nesta imagem abaixo:
Espero que tenham curtido. Se sim, me sigam no Linkedin para ver meus post, artigos.
Hoje vou ensinar como que você pode usar Node.js com Express e TypeScript para criar uma WebAPI. Não vou entrar no detalhe aqui de algum banco de dados em específico pois já tem outros tutoriais abordando bancos de dados aqui no blog, basta conectar as duas pontas. Vamos usar a memória do processo Node.js como armazenamento temporário, nos focando mais nos aspectos web da API mesmo.
Um ponto importante é que vou usar TypeScript aqui, mas que este não é um tutorial para quem nunca programou TypeScript antes. Se for o seu caso, recomendo que tenha um primeiro contato com este tutorial aqui.
Por fim, caso prefira, pode assistir ao vídeo abaixo ao invés de ler o tutorial, o conteúdo é o mesmo.
#1 – Criando o projeto
O primeiro passo é criar uma pasta na sua máquina para guardar os arquivos do projeto. A minha eu chamei de webapi e dentro dela deve rodar o comando para inicialização de projeto Node.js, como abaixo.
npm init -y
O segundo passo é instalarmos as dependências que vamos precisar, divididas em dois grupos: dependências de produção e dependências de desenvolvimento. A primeira lista é essa:
npm i express cors dotenv helmet morgan
A saber:
Express: webserver que vamos utilizar para a webapi;
CORS: pacote de segurança necessário para permitir comunicação futura com frontend;
Helmet: pacote de segurança para dar uma blindada básica na nossa webapi;
DotEnv: pacote de configuração para cuidar das variáveis de ambiente;
Morgan: pacote para logging de requisições no terminal;
A segunda lista é essa:
npm i -D typescript ts-node @types/express @types/cors @types/morgan
A saber:
Typescript: pacote para suporte à typescript no projeto;
TS-Node: pacote para execução de arquivos TS sem precisar de pré-transpilação;
@types/…: types dos pacotes que vamos usar, para reconhecimento na ferramenta;
O terceiro passo é inicializarmos o TypeScript em nosso projeto, o que devemos fazer com o comando abaixo.
npx tsc --init
Isso irá criar o arquivo tsconfig.json padrão, que eu recomendo que seja personalizado como abaixo. Explico na sequência as alterações.
target: diz respeito a versão do JS a ser usada na transpilação;
rootDir: onde estão os arquivos TS;
outDir: onde estarão os arquivos JS após transpilação;
ts-node: configurações específicas do TS-Node, onde coloquei uma configuração que reduz consumo de memória;
O quarto passo é criar um arquivo .env na raiz da sua aplicação, para colocar nossas variáveis de ambiente, sendo que vamos precisar somente de uma por enquanto.
# .env, don't commit to repo
PORT=3000
Lembre-se de colocar .env no seu .gitignore para não versioná-lo.
O quinto passo é criar dentro do seu projeto uma pasta src para guardar os fontes TS da nossa webapi. Dentro dela, crie uma pasta controllers, outra routers, outra repositories e outra models. Fora delas, crie dois arquivos TS, um server.ts e um app.ts. Sua estrutura final deve ficar como abaixo.
/webapi/
/src/
/controllers/
/models/
/repositories/
/routers/
app.ts
server.ts
.env
package.json
tsconfig.json
Especificamente sobre as 4 pastas e 2 arquivos que criamos por último, segue uma breve explicação da responsabilidade de cada um.
server.ts: módulo de inicialização do servidor web onde nossa webapi estará hospedada, módulo de infraestrutura;
app.ts: módulo de configuração da webapi, módulo de aplicação;
routers: pasta onde guardaremos os módulos de roteamento, que mapeiam os endpoints para as funções de controle;
controllers: pasta onde guardaremos os módulos de controle, que recebem as requisições roteadas e fazem os processamentos necessários;
models: pasta onde guardaremos os módulos de entidades, que contém a especificação delas;
repositories: pasta onde guardaremos os módulos de repositório, que contém as funções de leitura, exclusão, inserção, etc das entidades;
E por fim, vamos abrir nosso package.json e configurar os scripts que usaremos no projeto.
Assim, quando estivermos desenvolvendo, nós deixaremos a aplicação rodando com o comando “npm run dev”, enquanto que em produção, usaremos o “npm run compile” para transpilar TS para JS e depois “npm start” para subir a aplicação. Repare que estou usando Nodemon em ambiente de dev para manter o processo sempre rodando e que ele automaticamente detecta que você possui o TS-Node instalado e que os arquivos TS devem ser executados com ele.
E com isso finalizamos o setup inicial do nosso projeto de webapi.
#2 – Programando servidor e aplicação
Agora que você já tem o projeto minimamente configurado, vamos fazer um primeiro fluxo de teste para garantir que está tudo funcionando, além de já deixar a estrutura central da webapi pronta.
O primeiro passo é ir no seu app.ts e começar a trabalhar nele, pela importação dos módulos que vamos precisar. Nada de especial aqui, apenas os imports dos pacotes e alguns types do Express.
import express, { Request, Response, NextFunction } from 'express';
import cors from 'cors';
import morgan from 'morgan';
import helmet from 'helmet';
Com os módulos carregados, agora é hora de criar a aplicação Express e configurar os middlewares nela.
A primeira linha inicializa a aplicação Express, enquanto que as demais pluga os middlewares. O primeiro é o Morgan, com configuração minimalista de logs. O segundo é CORS, com configuração aberta para receber requisições de qualquer frontend. O terceiro é o Helmet, com a configuração padrão que nos protege de 11 vulnerabilidades comuns na web. O quarto middleware é o express.json() que é um body-parser para que nossa API possa receber dados JSON.
E os dois últimos e mais importantes middlewares neste momento são o de tratamento global onde qualquer requisição que chegar será respondida com um Hello World e o middleware de erro (último) que será ativado caso qualquer middleware anterior dispare uma exceção não tratada (expliquei melhor sobre error handling neste artigo).
Agora temos de ir no módulo server.ts e configurar nele a inicialização da nossa aplicação, como abaixo.
import dotenv from 'dotenv';
dotenv.config();
const PORT = parseInt(`${process.env.PORT || 3000}`);
import app from './app';
app.listen(PORT, () => console.log(`Server is running at ${PORT}.`));
Aqui começamos carregando as variáveis de ambiente com o pacote dotenv. Usaremos a variável PORT para, com a app importada, inicializar ela na porta configurada, imprimindo no console quando esse processo terminar.
Experimente agora subir a sua aplicação com npm run dev e testar ela via Postman. Qualquer request que fizer para localhost:3000 terá um Hello World como resposta. Caso nunca tenha usado o Postman antes, o vídeo abaixo pode ajudar.
Se você já consegue colocar para rodar a aplicação e fazer um GET ou POST nela obtendo um Hello World como resposta, esta etapa do desenvolvimento foi concluída.
#3 – Criando a camada de dados
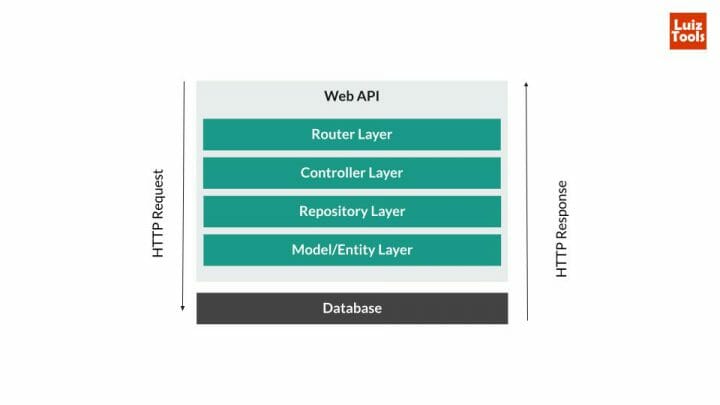
Agora que temos a estrutura inicial pronta podemos fazer a funcionalidade que quisermos na API seguindo a seguinte lógica: a requisição chega no app.ts e é roteada por algum router. O roteamento da requisição a leva até um controller que fará seu processamento. Caso ele precise de dados, usará repository da entidade que é o módulo responsável pelo acesso a dados, especificados pelo model. A imagem abaixo exemplifica esse fluxo, que é bem popular em webapis.
O primeiro passo é irmos na pasta models e dentro dela criarmos um model de exemplo. Usarei aqui um pseudo-cliente que você pode modificar à vontade. Ele terá apenas 3 campos, um id, um nome e seu CPF, como abaixo.
A especificação dos campos e a implementação do constructor dispensam explicações, mas o esquema que usei para gerar ids auto incrementais vale uma explicação. A ideia aqui é simular o comportamento dos bancos de dados que geralmente criam um id auto incremental a cada novo registro inserido. Como não usaremos banco de dados neste tutorial, usei uma variável static como gerador global de ids dos clientes, assim a cada novo “new Customer” que você chamar, o id será diferente.
Agora vamos criar o repository de customers, responsável pela gestão dos dados. Em uma situação real aqui você teria algum ORM como Sequelize por exemplo, mas como vamos simular essa parte dos dados, vou resolver tudo como sendo um array em memória. Para que fique mais próximo da experiência que terá com banco de dados real, que é sempre async, vou usar promises o que é algo completamente desnecessário nesse cenário simplificado, mas que vai te ajudar mais tarde quando plugar o banco. Assim, todas as funções retornam uma Promise, geralmente de Customer (para leituras) ou boolean (para escritas).
Abaixo, o início do CRUD de customers em nosso customerRepository.ts, explicado logo adiante.
import Customer from '../models/customer';
const customers: Customer[] = [];
async function getCustomer(id: number): Promise<Customer | undefined> {
return new Promise((resolve, reject) => {
return resolve(customers.find(c => c.id === id));
})
}
async function getCustomers(): Promise<Customer[]> {
return new Promise((resolve, reject) => {
return resolve(customers);
})
}
As duas primeiras funções são nossas funções de leitura/retorno dos dados (o R do CRUD). A primeira retorna um customer por id e a outra retorna todos. Em um cenário real, essa função que retorna todos não existiria e no lugar ela esperaria a quantidade ou página a ser retornada, já que facilmente os registros são na casa dos milhares ou milhões em bancos reais e retornar todos não seria nada performático e prático. Atenção especial ao uso que faço nesse módulo para algumas High Order Functions já que estamos lidando com um array.
Agora vamos para as próximas funções, de escrita, explicadas na sequência.
async function addCustomer(customer: Customer): Promise<Customer> {
return new Promise((resolve, reject) => {
if (!customer.name || !customer.cpf)
return reject(new Error(`Invalid customer.`));
const newCustomer = new Customer(customer.name, customer.cpf);
customers.push(newCustomer);
return resolve(newCustomer);
})
}
async function updateCustomer(id: number, newCustomer: Customer): Promise<Customer | undefined> {
return new Promise((resolve, reject) => {
const index = customers.findIndex(c => c.id === id);
if (index >= 0) {
if (newCustomer.name && customers[index].name !== newCustomer.name)
customers[index].name = newCustomer.name;
if (newCustomer.cpf && customers[index].cpf !== newCustomer.cpf)
customers[index].cpf = newCustomer.cpf;
return resolve(customers[index]);
}
return resolve(undefined);
})
}
async function deleteCustomer(id: number): Promise<boolean> {
return new Promise((resolve, reject) => {
const index = customers.findIndex(c => c.id === id);
if (index >= 0) {
customers.splice(index, 1);
return resolve(true);
}
return resolve(false);
})
}
export default {
getCustomer,
getCustomers,
deleteCustomer,
addCustomer,
updateCustomer
}
A função de adição é bem simples e apenas adicionei uma validação porque em um banco real isso poderia acontecer e também para ter um pouco mais de diversão codificando. Também me certifiquei de inicializar um objeto do tipo Customer, a fim de que a nossa geração automática de id funcione.
Na sequência, a função de atualização de cliente, onde eu verifico se o mesmo existe e, se ele existir, altero somente os campos que mudaram. Como estamos usando apenas objetos em memória, repare que procurei acessar a posição sempre por índice, para termos certeza que estamos alterando o objeto original.
E por fim, deixei como exemplo uma função de exclusão de cliente sem nada muito de diferente em relação ao que fizemos antes.
Com a camada de dados pronta, agora é hora de fazermos a camada de roteamento e controle. O ideal é que você teste bem esta camada antes de partir para a próxima, mas para que esse tutorial não fique extenso demais, recomendo que estude a parte de testes com esta guia de estudos aqui.
#4 – Roteamento e Controle
Agora o que temos de fazer é criar o customerRouter.ts e o customerController.ts. A responsabilidade do primeiro é tratar os endpoints, roteando eles para as funções corretas no controller. Já o controller deve receber a request e devolver a response, conforme o processamento necessário, o que geralmente envolve o uso de algum repository.
Vou começar pelo customerController.ts, abaixo, importando os módulos e types que usaremos e definindo as duas funções de leitura, explicadas mais adiante.
import { Request, Response, NextFunction } from 'express';
import Customer from '../models/customer';
import customerRepository from '../repositories/customerRepository';
async function getCustomer(req: Request, res: Response, next: NextFunction) {
const id = req.params.id;
const customer = await customerRepository.getCustomer(parseInt(id));
if (customer)
res.json(customer);
else
res.sendStatus(404);
}
async function getCustomers(req: Request, res: Response, next: NextFunction) {
const customers = await customerRepository.getCustomers();
res.json(customers);
}
No controller basicamente entra o tratamento das requests, pegando por exemplo os parâmetros de URL e o body (mais à frente). Esses inputs são usados para fazer as chamadas corretas ao repository e o retorno é devolvido como corpo da response HTTP (JSON) ou como status HTTP, dependendo do caso. As próximas funções não são muito diferentes.
async function postCustomer(req: Request, res: Response, next: NextFunction) {
const customer = req.body as Customer;
const result = await customerRepository.addCustomer(customer);
if (result)
res.status(201).json(result);
else
res.sendStatus(400);
}
async function patchCustomer(req: Request, res: Response, next: NextFunction) {
const id = req.params.id;
const customer = req.body as Customer;
const result = await customerRepository.updateCustomer(parseInt(id), customer);
if (result)
res.json(result);
else
res.sendStatus(404);
}
async function deleteCustomer(req: Request, res: Response, next: NextFunction) {
const id = req.params.id;
const success = await customerRepository.deleteCustomer(parseInt(id));
if (success)
res.sendStatus(204);
else
res.sendStatus(404);
}
export default {
getCustomer,
getCustomers,
postCustomer,
patchCustomer,
deleteCustomer
}
Resolvi nomear as funções de acordo com o verbo HTTP usado para chamar cada uma, mas isso não é obrigatório, qualquer nome vai funcionar. Nas funções de post e patch (adição e atualização, respectivamente), eu pego o body que veio na request (tipificado como customer) e passo ele para o repository. Opcionalmente é uma boa prática você validar esses bodys antes de passar para a próxima camada, mas não incluí neste tutorial para ele não ficar muito extenso. Se quiser se aprofundar neste tema recomendo este tutorial de validação c0m Joi.
A única função mais diferente é a de delete que somente pega o parâmetro que virá na URL, mas nada demais. Atenção aqui aos Status HTTP usados, que são os mais adequados para cada situação, a saber:
200: sucesso genérico (default);
201: sucesso em criação/adição;
204: sucesso sem retorno (geralmente exclusão);
404: não encontrado;
Agora que temos o controller finalizado, é hora de criar o customerRouter.ts para levar as requisições até as funções apropriadas, o que chamamos de roteamento.
Repare que o router é bem mais simples que os demais, é praticamente um mapeamento de cada endpoint com cada verbo HTTP para cada uma das funções do controller. Repare também o uso correto dos verbos HTTP para cada situação, a saber:
GET: retorno de dados;
POST: salvamento de nova entidade;
PATCH: atualização parcial de dados;
DELETE: exclusão de entidade;
Agora o ajuste final é incluir este router no app.ts, para que as requisições a /customers/ sejam enviadas pro router que acabamos de criar. Repare que a URL final de cada endpoint é a soma do path que está no app.ts + o path que está no router.
import customerRouter from './routers/customerRouter';
app.use('/customers/', customerRouter);
E com isso finalizamos o desenvolvimento da nossa webapi com Node.js, TypeScript e Express. Pode testá-la usando o postman agora e todas as rotas do CRUD devem estar funcionando. O próximo passo que recomendo que você faça agora é a adição de algum banco de dados como MongoDB, MySQL, PostgreSQL, MS SQL Server ou SQLite.
Veja nesse artigo um passo a passo de como criar uma arquitetura reutilizável utilizando Python
Arquitetura Limpa com Python
Clean Architecture tem sido um dos tópicos de grande interesse na comunidade de desenvolvimento de software por sua promessa de criar sistemas mais sustentáveis, testáveis e flexíveis.
Neste artigo, exploraremos como implementar Clean Architecture em um projeto Python, focando em um domínio de simples.
É importante destacar que a Arquitetura Limpa (Clean Architecture) pode ser aplicada em qualquer linguagem de programação. Neste artigo, escolhi apresentá-la por meio de exemplos em Python. No entanto, todos os conceitos e exemplos mostrados podem ser facilmente adaptados e replicados em outras linguagens
Bom, mas antes o que é Clean Architecture ?
Proposta por Robert C. Martin, a Clean Architecture visa separar as preocupações de uma aplicação, organizando o código de forma que as regras de negócio não sejam afetadas por detalhes como banco de dados, interfaces de usuário ou quaisquer fatores externos.
Essa abordagem facilita a manutenção e a expansão do código, além de tornar os testes mais acessíveis.
E pessoal, para que possamos desenvolver uma arquitetura robusta, os testes são de extrema importancia. Eles ajudam a garantir que o seu código seja manutenível.
Para o exemplo prático, nós construiremos um projeto que nos possibilita consultar o saldo de uma conta financeira.
A conta deve ter:
Titular
Saldo
Bom, vejamos quais são as camadas desta arquitetura:
Domain: Contém as entidades e regras de negócio.
Application: Inclui os casos de uso, orquestrando o fluxo de dados entre a interface do usuário e a camada de domínio.
Adapters: Transfere dados entre a aplicação e serviços externos.
Infra ou Infrastructure: Lida com detalhes de implementação, como acesso ao banco de dados e configurações de framework.
Tests: Para resposável pelos testes unitarios, de integração…etc
A seguir você tem um exemplo demonstrando esta estrutura básica:
Executando o comando pip install -r requirements.txt você pode baixar todos pacotes para o seu projeto.
Vejamos a seguir a implementação de cada uma destas camadas.
Domain
Iniciando pelo CORE principal do nosso sistema (o motivo dele existir), vejamos como criar/modelar o nosso dominio.
Vamos criar dois novos arquivos, uma para nossa Conta e um para nossa interface IContasRepository que é responsável por abstrair o acesso ao repositório de contas:
# domain/entities/conta.py
class Conta:
def __init__(self, id,titular, saldo):
self.id = id
self.titular = titular
self.saldo = saldo
Agora vamos criar a nossa interface IContasRepository:
# domain/interfaces/repositories.py
from abc import ABC, abstractmethod
class IContasRepository(ABC):
@abstractmethod
def obter_conta_por_id(self, conta_id: int):
pass
Analisando este trecho de código, nós estamos utilizando os pacotes ABC e abstractmethod que são componentes da biblioteca padrão do Python para definir uma interface abstrata, conhecida como classe base abstrata (ABC).
Esse método de design é empregado para estabelecer um contrato para subclasses, garantindo que métodos específicos (nesse caso, obter_conta_por_id) sejam implementados pelas subclasses concretas.
Application
Agora vamos implementar o caso de uso ConsultarSaldoUseCase, utilizando a interface do repositório criada no passo anterior:
# application/use_cases/consultar_saldo.py
from domain.interfaces.repository import IContasRepository
from isNullOrEmpty.is_null_or_empty import is_null_or_empty
class ConsultarSaldoUseCase:
def __init__(self, repo: IContasRepository):
self.repo = repo
def execute(self, conta_id: int) -> float:
conta = self.repo.obter_conta_por_id(conta_id)
if is_null_or_empty(conta):
raise Exception("Conta não encontrada.")
return conta.saldo
Neste trecho de código estamos implementando a interface `IContasRepository` e criando o método execute para o nosso UseCase.
Adapters
O próximo passo será a a implementação da camada de Adapters, isso inclui implementações concretas dos repositórios, e a Infrastructure configurada do ambiente técnico, como banco de dados e servidor web:
# adapters/repository/contas_repository.py
from domain.entities.conta import Conta
from domain.interfaces.repositories import IContasRepository
class ContasRepositoryMemoria(IContasRepository):
def obter_conta_por_id(self, conta_id: int) -> Conta:
return Conta(conta_id,"Thiago Adriano", 100.0)
Neste exemplo estamos simulando uma pesquisa no banco de dados para retornar o número da conta e o valor (mocado) de 100.0.
Infrastructure
Para deixar o nosso código organizado, vejamos como adicionar log nele.
Crie um novo arquivo chamado logging_config.py e atualize ele com o seguinte trecho de código:
Vivemos uma era em que a informação se consolidou como ativo estratégico central para empresas de todos os setores. Com a aceleração das tecnologias digitais e a expansão da economia de dados, surge um novo desafio: alinhar práticas corporativas às exigências de uma regulação global cada vez mais complexa e convergente. Observo que a preparação para essa nova fase passa por um redesenho profundo da governança de dados.
As empresas precisam compreender que as regulações não são mais eventos locais, mas parte de um ecossistema global interconectado.
Governança de dados
O Regulamento Geral de Proteção de Dados (GDPR) da União Europeia deu o tom em 2018, seguido por leis como a Lei Geral de Proteção de Dados Pessoais (LGPD) no Brasil, o California Consumer Privacy Act (CCPA) nos Estados Unidos, a Lei Chinesa de Proteção de Dados (PIPL) na China e mais recentemente discussões avançadas sobre uma regulação única na Associação de Nações do Sudeste Asiático (ASEAN) e uma revisão do GDPR pela Comissão Europeia.
Se trata de uma nova geração de normas que não apenas protegem dados pessoais, mas também impõem regras sobre inteligência artificial, transferência internacional de dados e segurança cibernética.
A Forrester, empresa de pesquisa e consultoria, realizou um estudo que mostrou que 70% das empresas planejam expandir sua governança de dados para abranger responsabilidade algorítmica e ética, além da privacidade, revelando que a governança de dados está deixando de ser apenas uma função de compliance para se tornar parte da estratégia de confiança digital e reputação das marcas.
Já uma pesquisa da Gartner, empresa de pesquisa e consultoria em TI e negócios, enfatizou que até 2026, mais de 60% das grandes organizações terão programas formais de governança de IA, impulsionados justamente pela pressão regulatória global.
Diante desse cenário, vejo cinco pilares essenciais para empresas que desejam uma governança de dados resiliente e preparada para o futuro:
Governança global, Compliance local
A governança precisa ser pensada em camadas. No topo, um framework global unificado, que estabeleça princípios gerais de proteção e uso ético dos dados, como transparência, accountability e privacy by design.
Em paralelo, deve haver compliance adaptado a cada jurisdição. O segredo está em mapear com precisão onde e como os dados são processados e alinhar essas operações às leis locais, sem perder a visão integrada do todo.
Data Stewardship como cultura corporativa
Não é mais suficiente ter um Data Protection Officer (DPO) ou um comitê de privacidade. A governança de dados precisa ser transversal, envolvendo áreas como TI, jurídico, compliance, recursos humanos e marketing.
O conceito de data stewardship, ou seja, responsabilidade compartilhada pela qualidade e segurança dos dados, deve ser incorporado à cultura da empresa. Isso exige treinamento contínuo e métricas claras de responsabilidade.
Arquitetura técnica resiliente
Do ponto de vista tecnológico, as organizações precisam investir em arquiteturas que suportem requisitos regulatórios futuros, como a portabilidade de dados.
Isso significa sistemas com capacidade de auditar, manter registros e rastrear dados, além de aplicar políticas de acesso e uso. A adoção de soluções baseadas em zero trust e criptografia avançada será cada vez mais mandatória.
Preparação para auditorias e certificações
As novas regulações indicam uma tendência clara: maior rigor na fiscalização e valorização de certificações internacionais, como ISO 27701 e NIST Privacy Framework.
As empresas que desejam operar globalmente precisam estruturar processos para responder prontamente a auditorias regulatórias e conquistar certificações que funcionem como selo de conformidade. Esse preparo inclui desde relatórios automatizados até simulações periódicas de incidentes.
Ética e responsabilidade social dos dados
Mais do que obedecer à lei, a governança de dados do futuro terá que responder às expectativas sociais sobre ética digital. Com o avanço da IA e da análise preditiva, surgem debates sobre discriminação algorítmica, vigilância e manipulação comportamental.
As empresas que se posicionarem de forma proativa, com comitês de ética em dados, políticas claras sobre uso de IA e compromissos públicos com a proteção dos direitos fundamentais, terão uma vantagem competitiva e reputacional em relação as suas concorrentes.
Entendo que conformidade regulatória é um ponto de partida, não o destino final. A verdadeira transformação está em enxergar a governança de dados como vetor de valor e confiança.
As corporações que compreenderem isso hoje, estarão preparadas para navegar com segurança e vantagem estratégica na economia digital global. O futuro da governança de dados não pertence aos que resistem à regulação, mas aos que a antecipam e a transformam em diferencial competitivo.
Popups estão em toda parte. Eles são amplamente utilizados para diversos fins, como exibir anúncios, captar leads (através de formulários), fornecer notificações ou oferecer interações rápidas com o usuário.
Embora possam ser úteis para chamar a atenção ou aumentar a conversão, seu uso excessivo ou intrusivo pode prejudicar a experiência do usuário, tornando importante o equilíbrio entre relevância e frequência.
Implementar um popup não é nenhuma tarefa de outro mundo, mas também não é tão trivial quanto gostaríamos. É ncessário criar a interface com HTML, customizar sua aparência com CSS e lidar com os diferentes casos de interação com o JS.
É por isso mesmo que geralmente usamos bibliotecas como o SweetAlert2 para fazer isso pra gente. Mas e se eu te disser que já existe uma API nativa para fazer isso? Estou falando da API popover! E sabe o melhor? Não precisamos nem de JavaScript! 😮
Para exemplificar o seu funcionamento, nós faremos uma pequena janelinha para que o usuário se cadastre na nossa newsletter.
A primeira coisa que precisaremos é de um botão que vai acionar a nossa caixinha:
Estava refletindo sobre os conhecimentos essenciais necessários para uma carreira de sucesso e percebi que há muitos aspectos que os gestores e os representantes de RH podem ignorar ou não compreender.
Posso não ser um perito em tudo, mas estou confiante de que posso resolver qualquer problema com que me depare da forma mais eficaz.
Tenho a capacidade de testar, verificar, tentar novamente, depurar e continuar a melhorar a minha abordagem até encontrar a melhor solução.
Se não sabe, a aquisição de conhecimentos leva tempo. Não vai aprender através de um simples vídeo, de um minuto de plataformas de redes sociais como o Instagram, o TikTok ou o YouTube.
A imagem abaixo dá uma ideia das várias responsabilidades e tarefas que os programadores e engenheiros de software podem encontrar nas suas funções.
Como programador, tem de saber:
1. Compreender a lógica subjacente ao algoritmo.
2. Familiarizar-se com a linguagem de computador que está a utilizar, incluindo sintaxe, expressões, loops, funções e métodos.
3. Conhecer as regras e os aspectos comerciais do sistema que está a codificar.
4. Ler a especificação e traduzi-la em código.
5. Compreender como armazenar dados na base de dados de forma eficiente e eficaz, tendo em conta o desempenho e a segurança.
6. Conhecer a estrutura da base de dados, incluindo tabelas, linhas, procedimentos de armazenamento, vistas, funções, operações de seleção, inserção, atualização e eliminação.
7. Determinar o melhor servidor para alojar o seu sistema ou aplicação e explorar as opções de implementação e monitorização do acesso e dos cliques.
8. Compreender como utilizar o Git para gestão de código e garantir a segurança do seu código em caso de falhas de hardware do computador. Aprender sobre branches, comandos Git e implantação.
9. Implementar mecanismos de autenticação e autorização para seu aplicativo, web ou sistema.
10. Considere a possibilidade de encriptar os dados durante todo o seu ciclo de vida, mas determine se o HTTPS por si só é suficiente.
11. Decidir qual a plataforma para desenvolver a sua aplicação, aplicação Web ou sistema, considerando opções como móvel, desktop, Web ou IoT.
12. Determinar se é necessária uma API e selecionar os métodos adequados para expor aos utilizadores.
13. Criar uma API segura e decida se deseja retornar dados JSON ou XML.
14. Projetar uma interface (UI) e uma experiência de usuário (UX) fáceis de usar usando HTML5. Certifique-se de que a UI seja responsiva e adequada para usuários que acessam o componente da Web em smartphones.
Todas as perguntas ou informações que você precisa verificar sobre o negócio, o tempo para concluir a criação do sistema, da Web ou do aplicativo e muito mais.
Eu lhe forneço informações gerais, mas também enfatizo a importância de aprender todas as etapas e os melhores métodos para isso.
Para avançar em sua carreira, é fundamental aprender todas as etapas e muito mais. Agora temos uma camada de IA para aprender e integrar nosso sistema a ela.
Para aprimorar minha carreira, tive que aprender Web, Desktop, API, Mobile e Banco de dados. Quais estratégias você empregou para avançar em sua carreira?
Não é fácil ser um desenvolvedor de programas hoje em dia, e não se esqueça de sempre aprender com uma nova tecnologia.
A Plataforma.Academy pode ajudá-lo a progredir em sua carreira com cursos e aulas dinâmicas usando metodologia e estratégia para aprender mais rápido do que outras escolas, como você pode ver em https://mauriciojunior.net
Tanto o desenvolvimento quanto o design web se tornaram opções muito atraentes no momento de escolher uma carreira profissional. De acordo com dados da Statista, até 2032, espera-se que haja 229 mil desenvolvedores web e designers de interface digital somente nos EUA.
Por aqui, para atender às projeções de crescimento da industria, o Brasil precisa qualificar mais de 630 mil profissionais da área de Tecnologia da Informação (TI) até 2027, segundo o Mapa do Trabalho Industrial da Confederação Nacional da Indústria (CNI).
Por outro lado, o mercado de trabalho também deverá desacelerar nos próximos meses. Especialistas estadunidenses preveem uma desaceleração geral na produção. Espera-se também que as empresas criem metade do número de empregos que ofereciam até março de 2025.
Sob este contexto, é salutar que talentos que aspiram a cargos relacionados a desenvolvimento e design web tomem algumas medidas para se destacar da concorrência. Felizmente, há várias maneiras de preparar e aprimorar a carreira profissional.
Encontre sua indústria
Pode parecer uma decisão fácil, mas é importante encontrar o setor em que você tem mais oportunidades de prosperar. Como fazer isso?:
Aproveite seus pontos fortes. Você se destaca na criação de experiências omnicanal ou se adapta bem às tendências? Então o comércio eletrônico pode ser para você. Você é apaixonado por criar experiências digitais que tenham a capacidade de influenciar a próxima geração? Educação parece uma ótima opção. Ao desenvolver seus talentos, você ganhará uma enorme vantagem competitiva. Por outro lado, você pode sufocar sua criatividade se ficar entediado com o que faz.
Entre em um setor resiliente. Organizações de todos os setores enfrentarão tempos desafiadores. No entanto, cinco deles têm maior probabilidade de serem “à prova de recessão”: comércio eletrônico, saúde, serviços financeiros, educação e jogos. Esses segmentos têm mais perspectiva de sobreviver a eventos disruptivos, como substituições de funções de IA e recessões.
Certifique-se de que seu tempo seja um investimento bem gasto. Sejamos honestos: alguns projetos não compensam todo o tempo e energia investidos neles. A menos que você tenha criado uma maneira de entregar produtos digitais rapidamente, pode não valer a pena quando você pode se concentrar em tarefas de maior valor.
Explore novas perspectivas e contribua com novas ideias
Para ter uma carreira de sucesso, você não precisa ter experiência em nenhum dos setores mencionados acima. Uma das melhores maneiras de se apresentar como um candidato único para uma vaga é ir para uma entrevista com uma ideia nova de como mudar as coisas.
Por exemplo, digamos que você seja apaixonado por desenvolver experiências digitais para veículos de mídia. Você pode ir à entrevista com ideias sobre como envolver um público digital e oferecer outras habilidades e serviços especializados que podem beneficiá-los.
Exemplos? Auditoria de sites ou aplicações, SEO, otimização de segurança e desempenho, controle de qualidade e testes, entre outros diferenciais. Isso pode denotar sua versatilidade e habilidades.
Colabore com seus colegas desenvolvedores e designers
Embora desenvolvedores e designers tenham responsabilidades diárias diferentes, ambos têm o mesmo objetivo final: oferecer as melhores experiências digitais possíveis para os usuários.
Para se destacar da concorrência, é importante que os desenvolvedores reservem um momento para considerar os desafios que os web designers enfrentam e vice-versa.
Para os desenvolvedores, isso significa que é importante aprender mais sobre princípios de design, como hierarquia visual, navegação, uso de grade e design responsivo, além de destacar o desejo de se envolver mais cedo no processo de design.
Fazer isso ajudará as equipes de RH e recrutamento a ver que você se importa com o funcionamento dos bastidores e também com o apelo visual do produto.
Da mesma forma, é aconselhável que os designers entendam as limitações técnicas com as quais os desenvolvedores normalmente trabalham. Entre outras, incluem:
Restrições de hardware, como poder de processamento, memória e armazenamento.
Restrições de software, como limitações de estrutura e biblioteca, sistemas legados e limitações de API.
Restrições de desempenho, como requisitos de latência e escalabilidade.
Restrições de segurança e privacidade, como medidas de conformidade, controle de acesso e criptografia de dados.
Prepare sua carreira de desenvolvimento e design para o futuro
À medida que a IA generativa continua a impulsionar a transformação digital e inúmeros avanços tecnológicos ainda estão por vir, o momento atual se mostra oportuno para desenvolvedores e designers.
Independentemente do cenário do mercado de trabalho, esses profissionais podem “proteger suas carreiras para o futuro” encontrando o nicho certo, ao trazer novas ideias para a mesa e trabalhar para entender seus colegas desenvolvedores e designers.
Com essas dicas, os profissionais de experiência digital estarão preparados para um futuro de sucesso, tanto a curto quanto a longo prazo.
Se você já usa o GitHub Copilot no dia a dia, prepare-se para conhecer o modo mais poderoso dessa ferramenta: o modo Agente. Ainda pouco explorado por muita gente, esse recurso é capaz de planejar tarefas, navegar por arquivos, executar comandos e editar código de forma autônoma, tudo a partir de um único prompt.
Neste post, quero te mostrar como o modo Agente funciona e como ele pode transformar sua rotina de desenvolvimento, especialmente em projetos novos ou mais complexos.
O que é o modo Agente?
O modo Agente permite que você envie um prompt de alto nível, como por exemplo “crie uma página de login com autenticação”, e o Copilot faz o resto. Ele traça um plano, identifica os arquivos relevantes, escreve o código necessário, executa comandos no terminal e repete o ciclo até concluir a tarefa.
Além de entender seu projeto como um todo, o modo Agente consegue manter o contexto por mais tempo. Isso significa que ele pode atuar em várias etapas e partes diferentes do seu código, sem perder a noção do objetivo inicial.
Você pode pedir para ele criar funcionalidades completas, corrigir bugs, gerar novos arquivos ou até montar a estrutura inteira de uma aplicação com base nas suas instruções iniciais.
Controle e confiança
É normal que esse comportamento mais autônomo cause estranhamento no início. Algumas pessoas podem sentir que estão abrindo mão de controle, enquanto outras veem nisso uma forma de acelerar o desenvolvimento e manter o foco no objetivo.
Eu, por exemplo, gosto bastante da liberdade que o modo Agente oferece quando estou começando um projeto novo do zero. Ele economiza tempo, evita tarefas repetitivas e me ajuda a sair da minha inércia inicial mais rápido (eu sempre dou uma travada quando começo algo novo).
Experiência prática: começando um projeto com o modo Agente a partir do README
Quer ver o modo Agente do Copilot em ação? Aqui vai um exemplo prático que você pode testar no seu próprio ambiente.
Vamos começar com um repositório vazio e adicionar apenas um arquivo README.md descrevendo o que queremos.
# Meu App de Tarefas
Quero um aplicativo web simples para gerenciamento de tarefas.
Funcionalidades:
- Adicionar, editar e excluir tarefas
- Marcar tarefas como concluídas
- Interface amigável com layout responsivo
Tecnologias:
- Frontend com React
- Backend com Node.js e Express
- Banco de dados com SQLite ou outro banco leve
Com esse README salvo no repositório, abra o projeto no VS Code com o GitHub Copilot habilitado em modo Agente.
No chat do Copilot, envie algo como:
Crie a estrutura inicial do projeto com base nas informações do README. Comece pelo backend e depois siga para o frontend.
A partir daí, o Copilot vai:
Criar a estrutura de pastas
Iniciar o projeto com os arquivos básicos (como package.json, index.js, App.jsx)
Gerar os endpoints do backend
Criar componentes iniciais de UI no frontend
Sugerir um banco de dados e conexão básica
Nem tudo vai sair perfeito, mas você já começa com um ponto de partida funcional. Essa ajuda inicial poupa tempo e tira a pressão de começar do zero
Quanto mais claro e detalhado o seu README (ou as instruções que você dá via prompt), melhor o Copilot entende o contexto e mais coerente será o resultado.
No nosso exemplo, que começou apenas com um README.md, agora eu tenho o seguinte:
Temos um Back End todo estruturados e só não tem nada no Front End porque eu queria terminar esse artigo logo e não fiquei esperando haha
Atenção sempre
Mesmo com toda essa autonomia, é importante continuar acompanhando o que está sendo feito. O modo Agente pode sugerir comandos inesperados ou modificar arquivos que você gostaria de manter como estão. Ou seja, como toda IA ele também alucina.
O segredo está no equilíbrio. Com bons prompts, instruções bem definidas e ajustes durante o processo, a experiência se torna produtiva, fluida e até divertida.
Vale a pena testar
O modo Agente é uma das funcionalidades mais avançadas do GitHub Copilot e pode ser um grande aliado no seu fluxo de trabalho. Ele não substitui a pessoa desenvolvedora, mas colabora ativamente, agilizando tarefas e ajudando a manter o foco no que realmente importa.
Se você ainda não testou, vale a pena experimentar. E se já testou, tente usá-lo com instruções personalizadas e objetivos mais complexos.
Pode ser o empurrão que faltava para tirar aquela ideia do papel.




















 O primeiro passo é irmos na pasta models e dentro dela criarmos um model de exemplo. Usarei aqui um pseudo-cliente que você pode modificar à vontade. Ele terá apenas 3 campos, um id, um nome e seu CPF, como abaixo.
O primeiro passo é irmos na pasta models e dentro dela criarmos um model de exemplo. Usarei aqui um pseudo-cliente que você pode modificar à vontade. Ele terá apenas 3 campos, um id, um nome e seu CPF, como abaixo.










