
Neste artigo, vamos explorar uma mudança significativa no Angular v21 que afeta a forma como testamos nossos componentes. O Angular v21 introduz o Vitest como a biblioteca de testes padrão, substituindo a antiga configuração Jasmine/Karma. Embora isso possa parecer apenas uma atualização de ferramentas, tem implicações profundas para nossas estratégias de teste.
A verdadeira mudança reside na adequação às diretrizes de estilo modernas do Angular, no encapsulamento apropriado e na cobertura de testes precisa.
Se você atualizou recentemente para o Angular v21 (ou migrou para o Vitest) e de repente notou lacunas de cobertura que não existiam antes, não se preocupe. Vamos explorar por que isso está acontecendo e como adaptar seus testes para atender às expectativas do Angular.
Este é um artigo de opinião sobre os próximos passos nos testes com Angular v21+.
O Modelo Mental Legado: Cobertura Exclusiva de TypeScript
Durante muito tempo, os aplicativos Angular foram testados usando:
- Jasmim + Karma
- Configurações baseadas em Jest
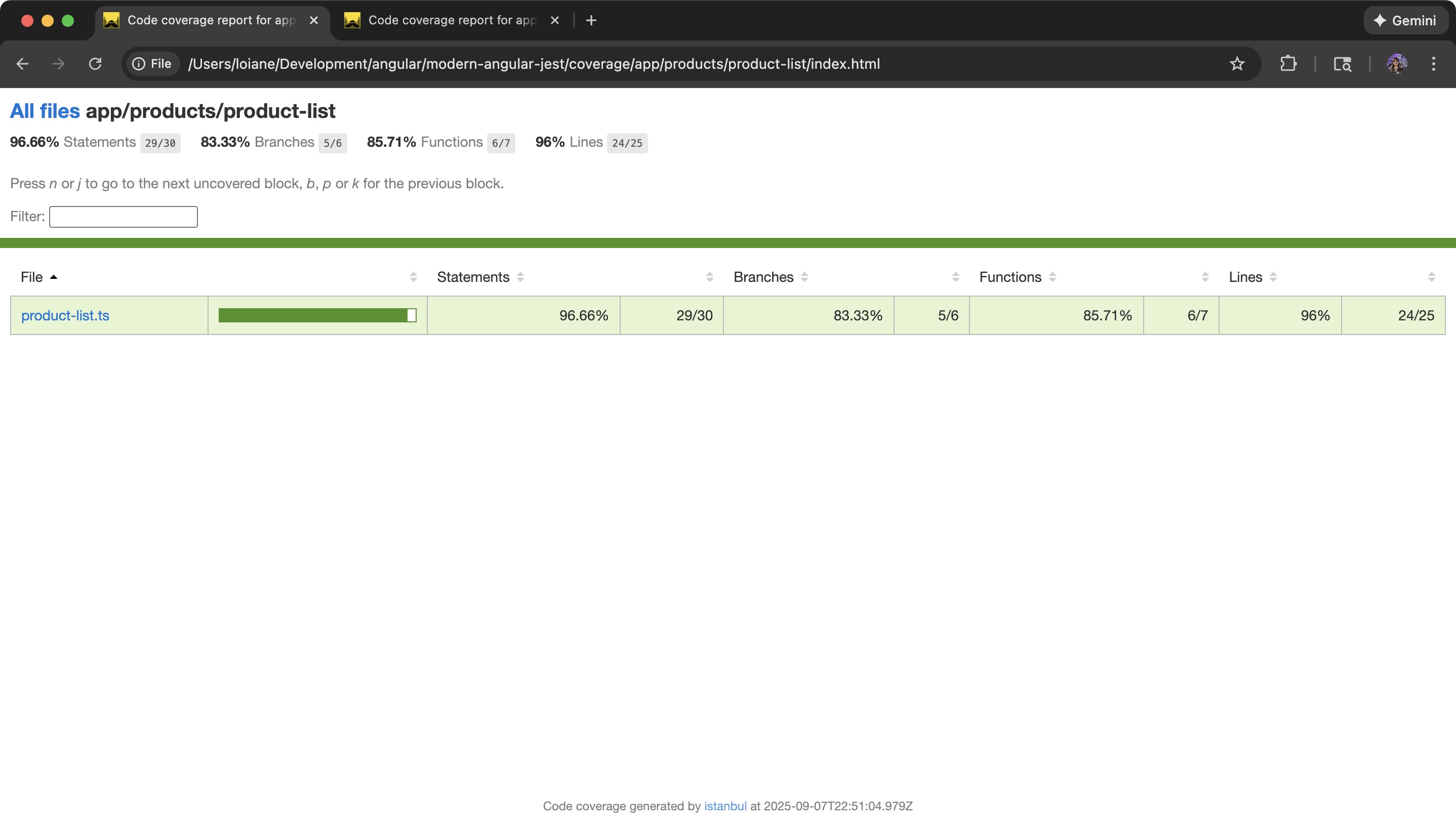
Independentemente do executor, a cobertura era efetivamente exclusiva do TypeScript :
.tsos arquivos foram instrumentados.htmlOs modelos geralmente eram ignorados.
Isso levou a um padrão de teste comum, no qual os desenvolvedores costumavam:
- Chame os métodos dos componentes diretamente (já que eles eram públicos).
- Ler ou modificar propriedades de componentes em testes (já que eram públicas)
- Afirmar sobre o estado interno
Enquanto o método fosse executado, a cobertura aumentava, mesmo que o modelo nunca exercesse essa lógica .
O resultado? Altas métricas de cobertura que pareciam ótimas no papel, mas não refletiam com precisão a confiabilidade da interface do usuário.
Angular v21 + Vitest: Os modelos agora fazem parte da cobertura de testes.
O Angular v21 altera a configuração de teste padrão para Vitest . A mudança mais significativa está na forma como a cobertura é relatada:
Os modelos HTML agora estão incluídos nos relatórios de cobertura.
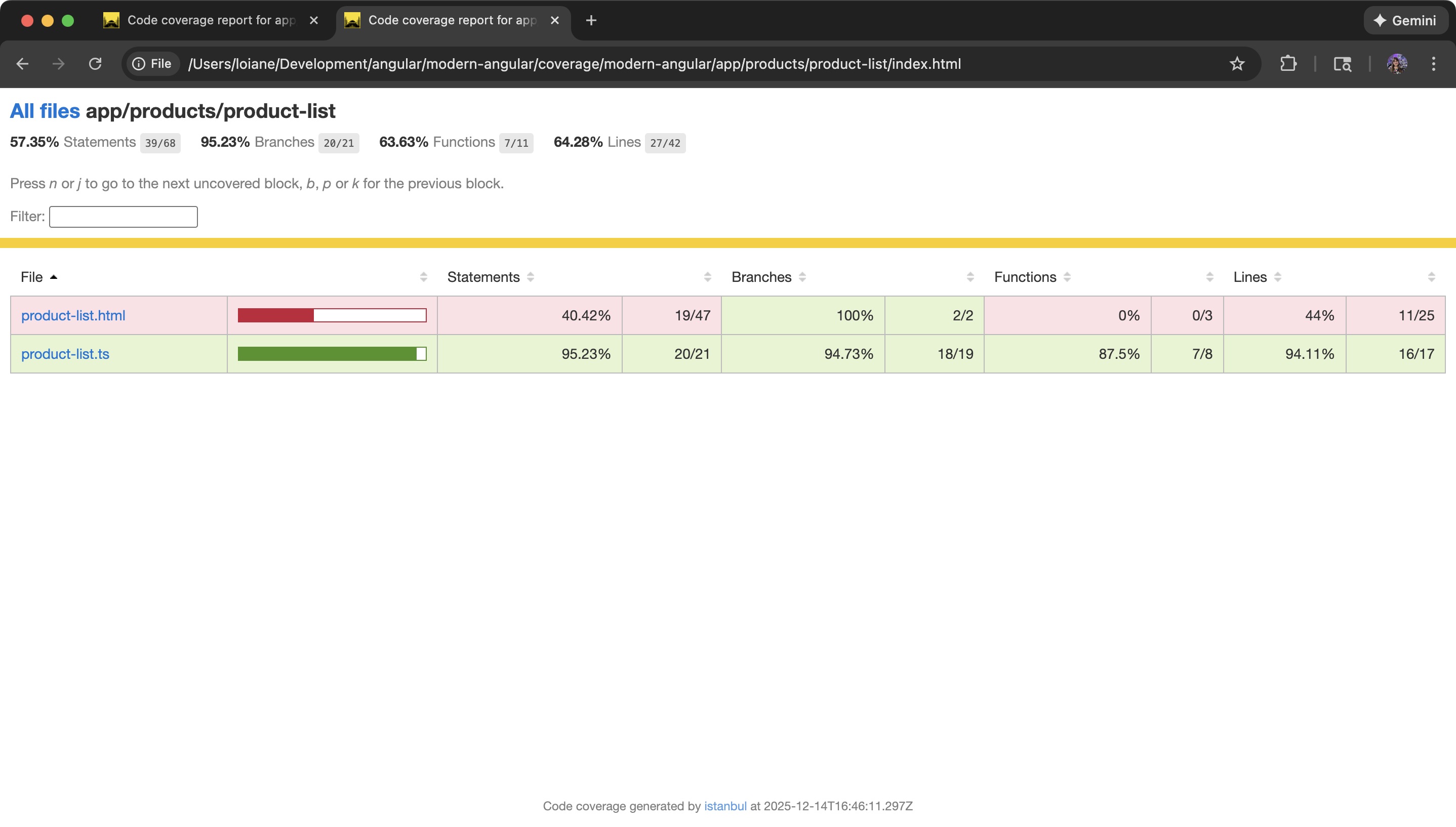
O que isso significa na prática? A cobertura agora inclui:
- Associações de eventos como
(click)e(change) - Renderização condicional (
@ife outros controles) - Diretrizes estruturais
- Caminhos de execução orientados por modelos
Como resultado:
- Chamar um método de componente diretamente não “encobre” mais a lógica do template.
- Agora, as lacunas de cobertura aparecem exatamente onde a interface do usuário não está sendo utilizada.
Isso não é uma regressão. É o Angular fornecendo uma visão mais precisa e honesta da saúde da sua aplicação.
O impacto dos membros protegidos
Desde a versão 20 do Angular, o guia de estilo do Angular recomenda:
Dê preferência ao acesso protegido para quaisquer membros que devam ser lidos a partir do modelo do componente.
Isso adiciona mais um desafio à abordagem de teste legada. Se um membro for `null` protected, ele não estará acessível no seu arquivo de teste. Você não pode simplesmente acessar o componente e verificar uma propriedade ou chamar um método diretamente.
O que isso significa? Mesmo que você quisesse ignorar o modelo e testar a lógica diretamente, o TypeScript não permitiria.
Portanto, temos duas forças nos impulsionando na mesma direção:
- O Vitest requer a execução de um modelo para cobertura.
- O Guia de Estilo do Angular restringe o acesso à lógica interna dos componentes.
A mensagem é clara: pare de testar detalhes de implementação. Comece a testar o comportamento.
Um exemplo real: componente ProductListComponent
Para ilustrar isso, vejamos um exemplo real. O ProductListComponentexemplo do meu modern-angularrepositório demonstra esse padrão:
app/products/product-list
Este componente foi projetado seguindo os padrões modernos do Angular:
- Lógica orientada a modelos : O modelo gerencia as interações do usuário.
- Membros protegidos : Propriedades e métodos usados apenas no modelo são marcados como
protected - API pública mínima : O componente expõe apenas o que é estritamente necessário.
Este design segue as recomendações que o guia de estilo do Angular vem incentivando desde a versão 20.
Padrão de teste legado (pré-v21)
Antes do Angular v21, um teste típico geralmente se parecia com isto:
it('filters products by category', () => {
component.selectedCategory = 'Books';
component.applyFilter();
expect(component.filteredProducts.length).toBe(2);
});
Por que isso pareceu correto?
- O método foi executado com sucesso.
- As afirmações foram aprovadas.
- As métricas de cobertura do TypeScript aumentaram.
No entanto, eis o que realmente aconteceu:
- O modelo nunca esteve envolvido no teste.
- Nenhuma interação do usuário (clique, entrada de dados, etc.) foi simulada.
- O teste validou detalhes da implementação, não o comportamento real.
Com o Vitest, a cobertura de HTML permanece intacta e os relatórios de cobertura revelam a verdade: o componente não foi totalmente testado .
O desafio: APIs protegidas não são fáceis de testar.
Em componentes Angular modernos:
- Propriedades e métodos exclusivos do modelo são marcados com
protected. - O TypeScript impede corretamente o acesso direto a esses membros a partir dos testes.
Isso cria atrito para estilos de teste legados. Soluções alternativas comuns incluem:
- Convertendo o componente para
any. - Métodos de criação criados
publicexclusivamente para fins de teste.
Mas, com a cobertura que leva em consideração os modelos, essas soluções alternativas falham por dois motivos:
- Eles violam os princípios de encapsulamento.
- Eles não melhoram a cobertura do modelo.
O Angular está basicamente nos dizendo: se o seu teste não passar pelo modelo, ele não conta.
A solução: Teste através do modelo
A solução não é lutar contra o framework, mas sim mudar a forma como testamos os componentes .
Em vez de invocar a lógica diretamente, devemos:
- Interagir com o DOM
- Eventos de gatilho
- Verifique a saída renderizada
Vamos refatorar o teste anterior para seguir esta abordagem:
it('filters products when a category is selected', async () => {
const select = fixture.nativeElement.querySelector('select');
select.value = 'Books';
select.dispatchEvent(new Event('change'));
fixture.detectChanges();
const items = fixture.nativeElement.querySelectorAll('.product-item');
expect(items.length).toBe(2);
});
O que está acontecendo aqui?
- A interação de teste começa com o modelo (como os usuários realmente usam seu aplicativo).
- A lógica protegida permanece protegida (encapsulamento adequado).
- A cobertura agora inclui TypeScript e HTML.
Este teste reflete como os usuários realmente interagem com o componente, garantindo uma aplicação mais robusta e confiável.
💡 Bônus : Você obtém cobertura de testes tanto para o modelo HTML quanto para o código TypeScript dentro do componente!
Que mudanças ocorrem na prática?
Com o Angular v21+, seus testes devem:
- Prefira a interação com o DOM em vez de chamadas de método.
- Afirme o comportamento visível , não o estado interno.
- Considere o modelo como o ponto de entrada.
O que você ganhará com essa mudança:
- Os testes tornam-se mais fáceis de refatorar.
- O encapsulamento melhora naturalmente
- Os números de cobertura finalmente refletem o uso real.
Isso está perfeitamente alinhado com a direção de design do Angular e com as melhores práticas modernas de teste.
Conclusão
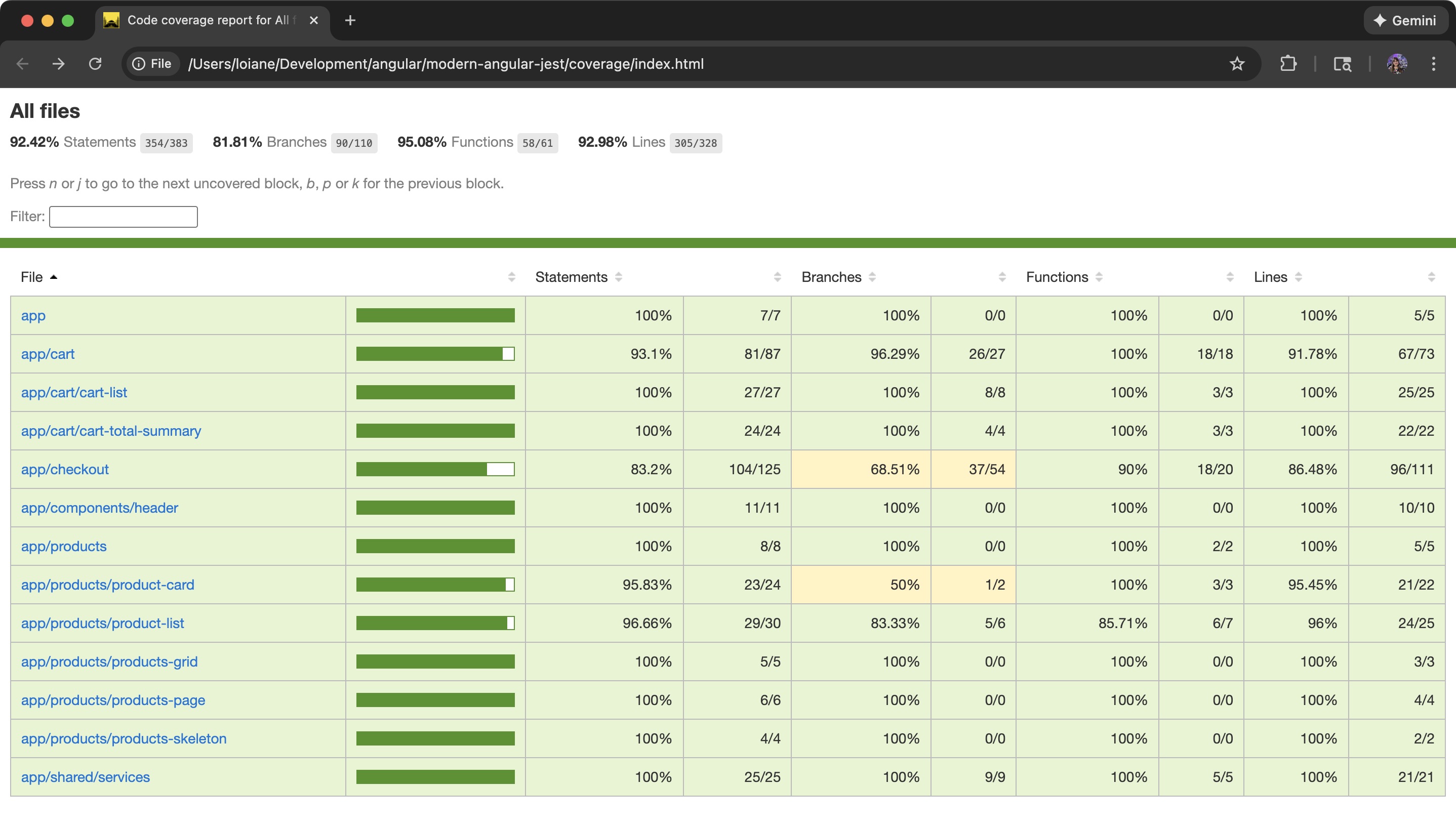
Ao atualizar para o Angular v21 + Vitest, espere o seguinte:
- Observe a queda na cobertura em componentes com uso intensivo de interface do usuário.
- Identifique testes que exercitem apenas a lógica TS.
- Reescreva os testes para acionar o comportamento por meio do modelo assim que você tornar as propriedades e os métodos protegidos.
Cobertura de versões pré-Angular v21 com Jest:
Angular v21 com Vitest:

Inicialmente, essa mudança parece desconfortável. Mas, na realidade, o Angular v21 está fazendo algo importante:
- Alinhar as diretrizes de estilo com as ferramentas.
- Incentivar testes baseados no comportamento
- Eliminando a falsa confiança da cobertura exclusiva de TS
O Angular não está tornando os testes mais difíceis. Está tornando os testes mais honestos .
Boa programação!






















