Eu quero contar para vocês como está sendo o Web Summit 2025 em Lisboa, onde a equipe do iMasters está acompanhando de perto tudo que acontece. Desde que chegamos à capital portuguesa, o clima tecnológico sugere que estamos num ponto de virada para o setor — e para nós.
Assim que desembarcamos em Lisboa, percebemos corredores gigantes, cheios de stands, mais de 70 000 participantes esperados, centenas de startups, investidores, gigantes da tecnologia, representantes de governos. O evento acontece de 10 a 13 de novembro de 2025.
E o iMasters está aqui não para “visitar”, mas para vivenciar: acompanhando sessões, entrevistas, ambientação, tendências emergentes — para trazer ao universo brasileiro o que de mais relevante está sendo debatido, testado ou apresentado.
Web Summit 2025
O que estamos acompanhando
Alguns eixos que chamam a atenção e que estamos monitorando com lupa:
Inteligência artificial (IA) — desde “vibe coding” (ferramentas que permitem criar aplicações com comandos mais intuitivos) até reflexões sobre ética, consumo de energia e infraestrutura para IA.
Startups e investimento global — o iMasters está conversando com fundadores, investidores, emergentes da América Latina e do Brasil para entender como o ecossistema local encaixa-se no panorama mundial.
Tecnologia + sociedade — regulação, soberania tecnológica, democracia digital. Exemplo: a fala da comissária europeia Henna Virkkunen sobre “technological sovereignty, security & democracy”.
Brasil / América Latina no mapa — monitoramos como empresas brasileiras estão se posicionando no evento, o que trazem de novidade, como interagem com players internacionais.
A riqueza da experiência para o universo da tecnologia
Para mim, Rafa, essa vivência traz uma série de insights que são ouro para quem trabalha com tecnologia:
A rede de contatos é impressionante: founders, investidores, policy-makers, grandes corporações, startups em fase inicial — todos no mesmo espaço.
A visão de futuro: ver o que está “logo ali” à frente — protótipos, conceitos, debates que hoje são “teóricos” e amanhã serão parte do dia a dia.
A inspiração: ouvir quem já “chegou lá”, quem lidera mudanças — isso instiga, estimula inovação, conecta ideias.
A conexão Brasil-mundo: estando aqui, o iMasters consegue trazer para o Brasil não apenas “tradução” do que acontece, mas contextualização — como o que está sendo debatido globalmente afeta nossas realidades locais.
Um Presente
Estar no Web Summit, como o iMasters está, acompanhando os painéis, conectando com gente, é muito mais que “estar presente”. É viver a tecnologia como está sendo moldada agora, e voltar com histórias, aprendizados e casos que podem (e vão) influenciar o Brasil.
Essa experiência é rica para todo o universo da tecnologia porque nos oferece:
real-time o que está sendo debatido globalmente
visibilidade das tendências que baterão aqui em breve
Se você trabalha (ou quer trabalhar) com Gestão de Projetos, provavelmente já se fez esta pergunta:
“Afinal, o que valerá mais a pena em 2026 — tirar a certificação PMP ou a Scrum Master?”
Com o mercado cada vez mais híbrido, misturando gestão tradicional e metodologias ágeis, a resposta dependerá do seu perfil, objetivos de carreira e momento profissional. Este guia vai te ajudar a decidir com clareza.
Por que certificações ainda importarão em 2026
Em um cenário onde o LinkedIn virou vitrine profissional, certificações continuam sendo sinais fortes de credibilidade — mas não são apenas sobre status.
Em 2026, elas representarão empregabilidade, atualização e diferenciação competitiva.
Empresas buscam profissionais que saibam entregar valor com método, dados e adaptabilidade. Tanto o PMP quanto o Scrum Master desenvolvem essas competências, mas por caminhos diferentes.
PMP x Scrum Master: o comparativo lado a lado
Como escolher a certificação certa para você
✅ Escolha PMP se você:
⚫ Já trabalha com gestão de projetos
⚫ Busca cargos estratégicos como Project Manager, PMO Specialist ou Gerente de Portfólio
⚫ Gosta de estrutura, planejamento e governança
⚫ Deseja ampliar sua visão estratégica e global de gestão
⚫ Atua (ou pretende atuar) em ambientes corporativos ou projetos de grande porte
✅ Escolha Scrum Master se você:
⚫ Está iniciando na área de projetos ou migrando de carreira
⚫ Quer ingressar no mundo ágil
⚫ Atua (ou deseja atuar) com times de tecnologia, produto ou inovação
⚫ Valoriza ambientes colaborativos, dinâmicos e de experimentação rápida
⚫ Prefere facilitar processos a controlá-los
Roadmap de Estudos: PMP 2026
1. Entenda o formato atual do exame
⚫ Baseado no PMBOK 7ª Edição + Agile Practice Guide
⚫ Foco em três domínios: People (42%), Process (50%), Business Environment (8%)
⚫ 180 questões em 230 minutos — questões situacionais e híbridas
2. Monte seu plano de estudo (8 a 12 semanas)
⚫ Complete as 35h de curso preparatório (obrigatórias para elegibilidade)
⚫ Faça pelo menos 3 simulados completos antes da prova
4. Agende e realize o exame
⚫ Disponível online ou presencial
⚫ Prepare-se mentalmente: resistência e concentração são essenciais
Roadmap de Estudos: Scrum Master
1. Escolha sua certificadora
⚫ PSM I (Scrum.org): mais técnica, sem curso obrigatório
⚫ CSM (Scrum Alliance): exige curso oficial, mais voltada à comunidade
2. Estude a base teórica (1 a 3 semanas)
⚫ Leia o Scrum Guide 2020 (documento oficial e gratuito)
⚫ Entenda os papéis: Scrum Master, Product Owner, Developers
⚫ Domine os pilares: transparência, inspeção e adaptação
⚫ Compreenda eventos, artefatos e compromissos do Scrum
3. Pratique com simulados
⚫ Meta: 90% de acertos antes da prova oficial
⚫ Use simulados gratuitos da Scrum.org
4. Tire a certificação e aplique o conhecimento
⚫ Participe de comunidades ágeis (Meetups, Agile Brazil, grupos no LinkedIn)
⚫ Comece a facilitar cerimônias, mesmo que informalmente
O veredito final
🎯 Se seu objetivo é liderar projetos complexos e crescer estrategicamente: vá de PMP.
🚀 Se você quer ser referência em agilidade e inovação: aposte no Scrum Master.
💡 E se puder, combine os dois: o mercado estará cada vez mais híbrido. Profissionais que dominam o framework ágil e o planejamento estratégico serão os mais disputados — e melhor remunerados.
Conclusão
Em 2026, a pergunta não será “qual certificação é melhor?”, mas qual fará mais sentido para o momento da sua carreira.
Ambas abrirão portas. A diferença estará no tipo de caminho que você quer trilhar.
E lembre-se: certificação não é ponto de chegada. É combustível para o próximo nível.
Qualidade e segurança no código são pontos fundamentais quando falamos em desenvolvimento e engenharia de software, e monitorar esses pontos durante as etapas de um projeto requerem atenção, pois ajudam a reduzir riscos operacionais e de segurança, além de ajudar a facilitar a manutenção e obter um retorno positivo em questão de confiabilidade do ativo de software quando dada a devida atenção nos apontamentos de códigos.
Uma forma de obter esses valores de qualidade e segurança são através de métricas, que normalmente são números gerados por um sistema com base em comportamentos e atividades que ocorrem durante a operação de um software/ambiente. Portanto, com as métricas é possível medir índices relevantes, quantificar e qualificar aspectos do software, contribuindo durante todo o processo de desenvolvimento de software e melhoria contínua.
Este artigo visa mostrar o processo de integração do SonarQube com Prometheus e Grafana, mostrando a implementação de uma solução capaz de gerar métricas, coletar as métricas e demonstrá-las em gráficos de maneira mais amigável e interpretativa.
Pré-requisitos para o ambiente
Esta seção é responsável por apresentar os pré-requisitos principais para que esta solução funcione e esteja apta a ser operada.
Ferramentas necessárias
Docker instalado.
docker --version
Docker Compose instalado (nas versões mais atuais do Docker o Compose já vem incluso).
docker compose version
Token do Vault e contexto configurados no terminal.
export VAULT_API_KEY="token vault gerado" # Token gerado no Vault
export VAULT_CONTEXT="operation/sonarqube" # Necessário para o Prometheus/Sonarqube
Usuário exclusivo do Prometheus cadastrado na base do SonarQube para acesso ao endpoint de métricas, e, token cadastrado para este usuário.
Token do usuário do Prometheus armazenado no Vault (key).
Arquitetura e funcionamento do ambiente da solução
Como esta solução é baseada em containers, foi adotado o Docker Compose para facilitar a execução deles com suas respectivas configurações particulares e também para facilitar o preparo do ambiente incluindo redes e volumes para cada um dos containers.
Arquitetura para o SonarQube
O SonarQube, até o momento, não dispõe de um plugin nativo que expõe métricas em um endpoint, sendo assim, para essa solução, foi utilizado um exporter desenvolvido pela comunidade que possibilita gerar e disponibilizar as métricas de contexto do SonarQube em um endpoint.
O exporter utilizado trata-se de um arquivo .jar na qual é copiado no diretório extensions/plugins dentro do container do SonarQube, e para facilitar este processo, conforme o Código 1, foi elaborado uma imagem do SonarQube que copia toda a estrutura do diretório extensions/ (linha 11) na qual inclui o arquivo Java, além de configurar permissão de execução do binário (linha 12).
1 FROM sonarqube:latest 2 3 # Instalar dependências para comunicação com o Vault 4 RUN apt-get update && \ 5 apt-get install -y curl jq gosu && \ 6 apt-get clean && rm -rf /var/lib/apt/lists/* 7 8 # Copia a pasta extensions preservando a estrutura dela 9 # incluindo o plugin/exporter para fornecer métricas ao 10 # Prometheus presente em extensions/plugins 11 COPY extensions /sonarqube/extensions 12 RUN chmod +x "/sonarqube/extensions/plugins/sonar-prometheus-exporter-1.0.0-SNAPSHOT.jar" 13 14 # Copia o wrapper e define permissões 15 COPY entrypoint.sh /entrypoint.sh 16 RUN chmod +x /entrypoint.sh 17 18 # Usa o entrypoint original via wrapper 19 ENTRYPOINT ["/entrypoint.sh"]
Esse foi O Código 1 – Arquivo Dockerfile para gerar imagem do SonarQube.
O endpoint de métricas do SonarQube estará disponível para acesso mediante usuário e senha, ou token, cadastrados na base do SonarQube (conforme a Figura 1), ou seja, em uma tentativa de acesso sem autenticação estabelecida é retornado o erro 401. Portanto, para esta solução, no SonarQube, foi cadastrado o usuário prometheus e gerado para ele um token para obter essa autorização.
Figura 1 – Usuário “prometheus” cadastrado na base do SonarQube.
O serviço do SonarQube configurado no arquivo Docker Compose, como mostrado abaixo no Código 2, foi incluído na rede de monitoramento monitoramento (linha 25) a fim do serviço SonarQube ter comunicação com os outros serviços de monitoramento da solução, e, para isso, essa rede de monitoramento foi configurada na seção de networks do Compose como uma rede já existente/externa a este Compose (linhas 57 e 58).
Esse foi o Código 2 – Arquivo docker-compose.yml para o ambiente do SonarQube
Arquitetura para o Prometheus e Grafana
O processo de customização de uma imagem para o Prometheus foi necessário devido ao fato da imagem oficial dele ser minimalista a ponto de não possuir gerenciador de pacotes para instalação de recursos necessários dentro do próprio container para interação e retorno do token armazenado no Vault.
Para que o token do usuário prometheus não seja importado como hard code no projeto, conforme o Código 3, foi necessária a implementação de um script entrypoint.sh no Dockerfile.prometheus para a execução do ambiente puxando o valor da key PROMETHEUS_TOKEN do Vault de forma segura para o arquivo de regras do Prometheus (linha 27 a 31).
1 #!/bin/sh 2 set -e 3 4 # Especificação do domínio 5 VAULT_DOMAIN="domain.com.br" 6 7# 🔒 Verificação de variáveis do Vault 8 [ -z "$VAULT_API_KEY" ] && echo "❌ VAULT_API_KEY não definido" && exit 1 9 [ -z "$VAULT_CONTEXT" ] && echo "❌ VAULT_CONTEXT não definido" && exit 1 10 11 VAULT_URL="https://${VAULT_DOMAIN}/v1/${VAULT_CONTEXT}" 12 echo "🔐 Buscando variáveis do Vault em $VAULT_URL" 13 14 RESPONSE=$(curl -sSf -H "X-Vault-Token: ${VAULT_API_KEY}" "$VAULT_URL") 15 16 # Gera arquivo temporário com export seguro 17 echo "$RESPONSE" | jq -r '.data | to_entries[] | "export \(.key)=\"\(.value)\""' > /tmp/.env.runtime 18 19 # Carrega variáveis no ambiente 20 set -a 21 . /tmp/.env.runtime 22 set +a 23 24 rm -f /tmp/.env.runtime 25 26 # Configura token Sonar se existir 27 if [ -n "$PROMETHEUS_TOKEN" ]; then 28 echo "📄 Configurando arquivo sonar..." 29 echo "$PROMETHEUS_TOKEN" > /etc/prometheus/sonar 30 chown prometheus-user:prometheus-group /etc/prometheus/sona 31 fi 32 33 echo "✅ Variáveis injetadas do Vault" 34 echo "🚀 Iniciando Prometheus..." 35 36 # Executa Prometheus como prometheus-user 37 exec su-exec prometheus-user:prometheus-group prometheus "$@"
Este foi Código 3 – Arquivo entrypoint.sh para obter o token no Vault.
O valor extraído da key PROMETHEUS_TOKEN do Vault por meio do entrypoint.sh é configurada no container dentro do arquivo sonar no diretório /etc/prometheus, pois, conforme o Código mostrado, nas configurações de regras do Prometheus ela é passada como token file (linha 17) para acesso ao endpoint de métricas do SonarQube /api/prometheus/metrics (linha 14), com target especificado para o serviço sonarqube (linha 16) derivado do Compose do ambiente do SonarQube. 1
Esse foi o Código 4 – Configurando o serviço do SonarQube nas regras do arquivo Prometheus.
A imagem customizada gerada com o Dockerfile.prometheus, apresentada abaixo no Código 5, utiliza a técnica de multi-stage build (linhas 1 a 12) onde na primeira fase são instalados os recursos necessários e o Prometheus, e na segunda fase (linhas 16 a 41) é feita de fato a cópia do binário do Prometheus e a configuração da imagem final onde é criado um usuário exclusivo para execução do Prometheus bem como as configurações de permissões e execução do entrypoint.sh. Além disso, em específico, na linha 32 é configurado o usuário prometheus-user como proprietário do diretório /prometheus/data no container que também é refletido como proprietário no host devido ao mapeamento efetuado para este diretório com o Docker Compose (Código 7, linha 10).
1 #### Dockerfile seguro para Prometheus + Vault 2 FROM alpine:3.22.1 AS builder 3 4 WORKDIR /tmp 5 6 # Instala ferramentas necessárias apenas para build 7 RUN apk add --no-cache curl tar 8 9 # Baixa e extrai Prometheus (arquitetura amd64 recomendada) 10 RUN curl -sSL https://github.com/prometheus/prometheus/releases/download/v3.6.0/prometheus-3.6.0.linux-amd64.tar.gz \ 11 | tar -xz && \ 12 mv prometheus-3.6.0.linux-amd64/prometheus /tmp/prometheus 13 14 # --------------------------------------------------------------- 15 16 FROM alpine:3.22.1 17 18 # Cria usuário não-root 19 RUN addgroup -S prometheus-group && adduser -S prometheus-user -G prometheus-group 20 21 WORKDIR /prometheus 22 23 # Instala apenas dependências necessárias no runtime 24 RUN apk add --no-cache su-exec jq curl 25 26 # Copia binário Prometheus do builder 27 COPY --from=builder /tmp/prometheus /usr/local/bin/prometheus 28 29 # Diretórios de configuração e dados 30 RUN mkdir -p /etc/prometheus && \ 31 mkdir -p /prometheus/data && \ 32 chown -R prometheus-user:prometheus-group /prometheus /etc/prometheus 33 34 # Copia entrypoint e aplica boas práticas 35 COPY entrypoint.sh /prometheus/entrypoint.sh 36 RUN sed -i 's/\r$//' /prometheus/entrypoint.sh && \ 37 chmod 755 /prometheus/entrypoint.sh && \ 38 chown prometheus-user:prometheus-group /prometheus/entrypoint.sh 39 40 ENTRYPOINT ["/prometheus/entrypoint.sh"] 41 CMD ["--config.file=/etc/prometheus/prometheus.yml", "--storage.tsdb.path=/prometheus/data"]
Esse foi o Código 5 – Dockerfile para gerar a imagem do Prometheus com interação com o Vault..
Ao passo que foi gerado o arquivo Dockerfile.prometheus, foi também gerado o arquivo Dockerfile.grafana (Código 6) para customização da imagem do Grafana, adaptando as permissões e o usuário na qual irá executar o Grafana dentro do container. Além disso, a customização da imagem do Grafana também se justifica pelo processo de padronização das configurações do Docker Compose para a execução dos serviços (modo build).
1 FROM grafana/grafana:11.2.0 2 3 # Garante que /var/lib/grafana e /etc/grafana tenham UID/GID corretos 4 RUN mkdir -p /var/lib/grafana/plugins /etc/grafana && \ 5 chown -R 472:472 /var/lib/grafana /etc/grafana 6 7 # Retorna para usuário grafana (472) 8 USER 472
Esse foi o Código 6 – Dockerfile para gerar a imagem do Grafa
No Código 7 é exibido o arquivo docker-compose.yml onde é configurada a execução do ambiente de monitoramento. Para a comunicação do Prometheus com o Vault, foi inserido as variáveis de ambiente VAULT_API_KEY e VAULT_CONTEXT (linhas 14 e 15). Além disso, também foi necessário estabelecer um nome fixo (linhas 38) para a rede de monitoramento em que o Prometheus e o Grafana fazem parte para facilitar o ingresso do serviço do SonarQube que é executado a partir de outro arquivo Docker Compose (Código 2). 1 services:
Esse foi o Código 7 – Docker Compose para preparar e executar o ambiente de monitoramento.
Diagrama da Arquitetura
Na Figura 2 é demonstrado, de forma simples, o diagrama da arquitetura desta solução visando facilitar o entendimento de forma visual, onde é mostrado os três containers (SonarQube, Prometheus e Grafana) fazendo parte da mesma rede para terem comunicação (monitoramento).
Além disso, no diagrama também é demonstrada a interação entre cada componente da solução, onde o Exporter inserido no container SonarQube fornece um endpoint de métricas, e o Prometheus, além de coletar essas métricas neste endpoint, se comunica com o Vault recebendo o token para ser configurado nas regras.
Por fim, é apresentado o Grafana que realiza a consulta de métricas armazenadas pelo Prometheus para gerar os dashboards.
Figura 2 – Diagrama da arquitetura da solução.
Execução do ambiente
Para a execução do ambiente, tanto o ambiente de monitoramento quanto o ambiente do SonarQube, é necessário informar no terminal o token e contexto do Vault, conforme informado na seção de pré-requisitos deste documento.
Após informado o token e contexto do Vault, é preciso primeiro ter o ambiente de monitoramento em execução, pois é nele que é criada a rede na qual o SonarQube irá integrar-se posteriormente.
Abaixo está o comando para iniciar os containers e preparar o ambiente. Primeiro, execute o comando no diretório do ambiente de monitoramento. Em seguida, utilize este mesmo comando para executar no diretório correspondente ao ambiente do SonarQube.
docker compose up -d # Inicia os containers
Obs: Quando há alterações em arquivos externos ao docker-compose.yml como por exemplo, Dockerfiles, códigos ou arquivos que estão relacionados ao Dockerfile, se faz necessário executar o comando com a flag --build para forçar o build das imagens, assim, considerando o que foi alterado fora do docker-compose.yml. Exemplo:
docker compose up -d --build # Inicia os containers com build das imagens
Configuração do Grafana
Com a solução toda em execução, para configurar o Grafana, basta fazer a configuração da fonte de dados com o Prometheus indicando o hostname e porta do service do Prometheus (server URL em Connection) e salvar a conexão, conforme demonstrado na Figura 3 abaixo. Além disso, na Figura 3 é destacado na URL da página o UID desta conexão de fonte de dados, e esta informação será útil na importação de um dashboard pronto a seguir.
Figura 3 – Configuração da fonte de dados com o Prometheus
Após a configuração da fonte de dados, no Grafana, é possível construir os dashboards a partir das métricas coletadas e disponíveis na fonte de dados, porém, para este ambiente, e, demonstrado na Figura 4, foi utilizado a importação via modelo JSON de um dashboard pré-configurado disponibilizado pela comunidade, podendo ser configurado no Grafana em painéis de controle bastando alterar todas as ocorrências de uid do datasource do arquivo JSON com o uid da fonte de dados correspondente, conforme exemplo em destaque na Figura 3
Figura 4 – Importação de dashboard via JSON alterando o UID da fonte de dados
Validação e funcionamento
Nesta seção será mostrado o ambiente em funcionamento no host em que ele está presente e também na interface web na qual os serviços podem ser acessados e visualizados pelo navegador.
Validando no servidor
No host onde o Docker está operacional, utilize o seguinte comando para mostrar os containers em execução, sendo que, este mesmo comando deve ser informado no terminal estando nos diretórios correspondentes de cada ambiente (monitoramento e SonarQube).
docker compose ps # Exibe os containers de cada projeto Compose
Na Figura 5 são mostrados em execução os containers que compõem o monitoramento, grafana e prometheus.
Figura 5 – Containers da solução de monitoramento
Na Figura 6 é exibido o container do sonarqube em execução, juntamente com o container do Postgres na qual o SonarQube precisa para se manter.
Figura 6 – Containers da solução do SonarQube.
Verificando as configurações do container sonarqube, conforme a Figura 7, nota-se que ele está fazendo parte da rede de monitoramento, possibilitando assim a comunicação entre ele e o Prometheus.
Figura 7 – Container do SonarQube na rede de monitoramento
É possível encontrar os três containers fazendo parte da mesma rede inspecionando esta rede de monitoramento, conforme demonstrado na Figura 8.
Figura 8 – Mostrando os três containers ao inspecionar a rede de monitoram
Validando no navegador
Abaixo, na Figura 9, é demonstrado o Exporter do Prometheus presente na interface administração do SonarQube, havendo também, por uma ventura necessidade, a possibilidade de ativar ou desativar métricas nas quais este Exporter prove para o Prometheus coletar.
Figura 9 – Prometheus Exporter instalado no SonarQube
Todas essas métricas que o Exporter disponibiliza são do tipo gauge, ou seja, sofrem incremento ou decremento ao longo das análises do projeto. Sendo assim, as possíveis métricas que este Exporter disponibiliza são:
1. sonarqube_complexity: Complexidade ciclomática;
2. sonarqube_security_hotspots: Pontos críticos de segurança;
3. sonarqube_sqale_index: Esforço total (em minutos) para corrigir todos os problemas do componente e atender aos requisitos;
4. sonarqube_duplicated_lines: Linhas duplicadas;
5. sonarqube_ncloc: Linhas de código sem comentários;
6. sonarqube_bugs: Erros (bugs);
7. sonarqube_vulnerabilities: Vulnerabilidades;
8. sonarqube_lines: Linhas totais;
9. sonarqube_violations: Problemas;
10. sonarqube_code_smells: Indícios de má qualidade;
11. sonarqube_alert_status: Status do projeto em relação ao seu limite de qualidade (quality gate);
12. sonarqube_coverage: Cobertura por testes;
13. sonarqube_lines_to_cover: Linhas que devem ser cobertas por testes.
Na configuração deste Exporter, ele por padrão indica o endpoint de métricas como sendo o …/api/prometheus/metrics, portanto, assim como feito na configuração do arquivo de regras do Prometheus, este mesmo caminho foi mantido como padrão. Na Figura 10 é mostrado este endpoint na qual o Prometheus acessa para coletar as métricas.
Figura 10 – URL onde as métricas são expostas.
Abaixo, na Figura 11, é exibido a tela do Prometheus na qual contém os targets que foram configurados para ele puxar as métricas, onde, nota-se o target do SonarQube com o service, endpoint e labels especificadas.
Figura 11 – Target do SonarQube sendo monitorado pelo Prometheus.
No Grafana, após feita a configuração de fonte de dados com o Prometheus, é possível configurar dashboards com gráficos e visualizações baseados nas métricas coletadas pelo Prometheus. Abaixo, na Figura 12, é demonstrado um exemplo de dashboard configurado com as métricas coletadas pelo Prometheus.
Figura 12 – Painel do Grafana com gráficos baseados nas métricas coletadas.
Resultados
Neste estágio inicial, os ambientes de monitoramento e o de análise de qualidade de código foram devidamente configurados e estão operando conforme o esperado. Embora os indicadores e métricas ainda estejam em processo de alimentação, é possível visualizar os painéis e compreender a estrutura que permitirá, futuramente, realizar uma análise mais detalhada da evolução do projeto.
A integração com o SonarQube e o Grafana estabelece uma base sólida para o acompanhamento contínuo da qualidade e segurança do código, viabilizando decisões técnicas futuras baseadas no cenário real em que o projeto é desenvolvido e nas métricas, conforme forem sendo consolidadas nos gráficos.
Com os dados do SonarQube consolidados em gráficos, ao longo do tempo, é possível analisar a evolução de indicadores, como complexidade, densidade de comentários, duplicação de códigos, entre outros. Esses dados facilitam a identificação de tendências, gargalos, e aspectos que demandam atenção, e com isso facilitam a tomada de decisão para melhorias nos processos de qualidade e segurança de código, alinhados às boas práticas.
Conclusão
Com a solução implantada, o ambiente está apto a receber dados/métricas para alimentar os gráficos referente às análises do SonarQube, e com isso, impactar positivamente com o monitoramento contínuo.
Com a possibilidade de monitorar e acompanhar os indicadores do sistema, o processo de melhoria contínua é reforçado por decisões mais assertivas, baseadas em dados reais e atualizados constantemente.
Portanto, esta integração do SonarQube com o Prometheus e Grafana não trata-se apenas de uma questão técnica, mas sim de um passo estratégico em direção à qualidade, segurança e confiabilidade.
Referências
● Docker Networking: https://docs.docker.com/engine/network/
● Networking in Compose: https://docs.docker.com/compose/how-tos/networking/
● Sonar metrics exporter: https://github.com/DomGiorda/sonar-metrics-exporter
● Prometheus Configuration: https://prometheus.io/docs/prometheus/latest/configuration/configuration/
● Build your first dashboard: https://grafana.com/docs/grafana/latest/getting-started/build-first-dashboard/?pg=dashboards&plcmt=hero-btn2
● Understanding measures and metrics: https://docs.sonarsource.com/sonarqube-server/user-guide/code-metrics/metrics-definition
Aprenda como usar o Corepack, a ferramenta que causou uma polêmica no mundo do Node.js
Se você acompanhou a polêmica ao redor do ambiente Node.js e NPM em 2024, você provavelmente já deve saber sobre o que eu vou falar. Mas hoje, quero mostrar pra você o que é o Corepack, a ferramenta que promete acabar com a guerra entre os gerenciadores de pacotes do Node!
Mas primeiro, um pouco de história!
Sobre o NPM
Desde que o Node foi criado, o NPM sempre foi o gerenciador de pacotes principal. Sendo embutido diretamente no binário do runtime e permitindo que você instalasse pacotes de forma muito simples e fácil.
Existem teorias dizendo que o criador do NPM, Isaac Schlueter, forçou a adoção do NPM pelo Node, de certa forma coagindo o pessoal a incluir ele no binário. O que não é verdade, o NPM foi um acordo entre ambos Isaac e Ryan Dahl para suprir a necessidade de uma comunidade crescente de usuários, a de ter uma forma simples de instalar pacotes externos.
Por muitos anos, o NPM foi o único local onde você podia publicar e baixar pacotes para o Node.js, isso não é mais verdade desde que tivemos o advento de outros como Yarn e PNPM
Então o NPM foi incluso no Node mesmo antes de ele se tornar uma corporação lucrativa comprada pelo GitHub em 2020 e, quando o GitHub foi comprado pela Microsoft, incluída no catálogo deles também.
O que se tirou disso é que, desde 2009, o NPM tem a maior fatia do mercado de managers, não que isso signifique alguma coisa prática, porém, tendo praticamente o monopólio de como os pacotes são baixados e utilizados, o NPM praticamente ditava como os pacotes precisavam ser criados, inclusive muitas das funcionalidades do Node foram criadas com ele em mente como, por exemplo, o fato de que qualquer pacote que não tenha um prefixo vai, automaticamente, ter o gerenciador setado para o NPM.
Esse acoplamento próximo do Node permitiu que o NPM ganhasse uma vantagem quase impeditiva para qualquer outro package manager florescer, basicamente muita gente viu isso como uma forma de eliminação de concorrência, como essa talk da CJ Silverio (ex CTO do NPM) mostra:
Mas e agora? Como ficam os demais gerenciadores? O fato é que, quando o NPM se tornou quase inutilizável devido à demora de instalação de pacotes, outras pessoas se moveram para criar outros gerenciadores, como o Yarn e o pnpm. A partir daí começou a guerra dos gerenciadores de pacotes. Uma guerra que, assim como a dos browsers, tinha e tem um monopólio grande de um sistema já estabelecido.
Mas isso tudo pode mudar com o Corepack.
O que é o Corepack
O Corepack é uma ferramenta que agora já vem junto ao Node.js desde a versão 14.19, assim como o NPM, mas ao invés de ser um package manager, ele é todos os package managers.
Essa ferramenta permite que você não só escolha um package manager que você queira, como também permite que você instale qualquer um deles sem precisar ir pelo longo processo de baixar o binário e instalar globalmente, etc… Basta rodar:
corepack enable&& corepack enablenpm
Esse comando ativa o Corepack para todos os pacotes do seu sistema, globalmente. O mesmo vale para o Yarn e pnpm. Ou seja, o Corepack é uma forma de você utilizar qualquer package manager que você ou o seu projeto estejam utilizando no momento, e ainda dizer para pessoas que vão utilizar o seu projeto qual é o package manager preferido (ou obrigatório).
🤖
Como você pode imaginar, a reação do NPM a essa ferramente não poderia ter sido outra, eles foram veementemente contra adotarem o protocolo, porque isso significaria também que o NPM iria parar de ser embutido no binário do Node.
Como usar o Corepack
Para utilizar o Corepack é bastante simples, vá no seu arquivo package.json e crie uma nova chave chamada packageManager, essa chave precisa ter o valor de yarn, npm ou pnpm, porém não qualquer valor, você também precisa especificar uma versão para o pacote:
Você não pode usar notações como pnpm@latest ou yarn@^10.0.0 (nem omitir a versão como pnpm diretamente). Mas ai que a mágica acontece.
Se você tiver um pacote ou projeto com a seguinte configuração no seu package.json:
{
"packageManager": "pnpm@9.1.4"
}
E tentar rodar npm install, você vai ter um erro dizendo:
Usage Error: This project is configured to use pnpm
Agora, se você digitar pnpm install, você vai ter uma outra mensagem:
Corepack is about to download https://registry.npmjs.org/pnpm/-/pnpm-9.1.4.tgz.
Do you want to continue? [Y/n]
E o mesmo vale para o Yarn.
O que o Corepack faz é interceptar chamadas para o Yarn e o pnpm, mas ele não faz o mesmo para o NPM, por isso precisamos de corepack enable npm, para que ele também intercepte as chamadas do NPM e faça a mesma coisa.
Agora você pode usar qualquer package manager, em qualquer repositório, a qualquer momento.
Conclusão
Enquanto essa é uma espécie de vitória para a comunidade em ter mais opções de forma mais justa, vale ressaltar que o NPM é uma das maiores ferramentas e provavelmente uma das principais razões pela qual o Node é o que é.
Então temos que ser gratos a eles também por ter feito todo esse trabalho desde 2009 e ter mantido tão bem a comunidade e a gestão de pacotes para que todos os usuários pudessem prosperar em um ambiente muito mais fácil e mais intuitivo.
Além disso, é importante dizer que, ao embutir o NPM dentro do Node, a gente ganha algumas coisas. Uma delas, se não a principal, é o fato de que a gente sabe que a versão atual do Node sempre vai funcionar com a versão instalada do NPM, isso facilita muito na hora de fazermos a gestão dos pacotes, porém é um problema maior para o time do Node já que uma nova versão tem que ser sincronizada entre os dois binários.
Por outro lado, usar sempre o Corepack da forma como ele é, não é muito intuitiva, portanto desacoplar o NPM por padrão pode tornar a vida de quem está querendo só instalar ou utilizar um pacote do Node bem mais complicada, por isso que essa polêmica não é tão simples assim!
É comum usarmos o Console como ferramenta nas nossas aplicações com Node, seja para validar algum dado, expor alguma mensagem/erro importante ou então ajudar no debug de dados. Entretanto, da maneira como isso é feito nativamente tem pouco apelo visual, afinal de contas, todas as mensagens tem a mesma cara.
Com o chalk — biblioteca de código aberto disponível no GitHub com mais de 13k estrelas no GitHub e atualmente na versão 3.0.0 — conseguimos aplicar vários tipos de estilos as mensagens do terminal.
Para testá-la precisamos inicializar um projeto com o npm. Para garantir que o resultado seja exatamente igual ao que mostrarei aqui, certifique-se de instalar como dependência a versão 3.0.0.
npm i chalk@3.0.0
Vamos criar um arquivo app.jse criar nossa primeira mensagem estilizada usando o método green().
Bacana, né? Vamos explorar mais algumas funcionalidades do chalk.
Estilizando de forma encadeada
Como a página oficial da biblioteca diz, o chalk possui uma API flexível que nos permite encadear e aninhar os estilos. Isso significa que podemos, por exemplo, aplicar negrito e cor em uma mensagem em uma tacada só:
const msg2 = chalk.bold.red("Hello World!");
console.log(msg2);// ou chalk.red.bold , a ordem não importa!
A ordem das chamadas não importa, o resultado é o mesmo:
Press enter or click to view image in full size
Estilizando mensagens usando o chalk e sua API flexível
Além disso, também podemos aninhar estilos. Como por exemplo:
As strings “Hello” e “World” possuem características distintas, mas ambas herdarão o negrito. Veja só:
Press enter or click to view image in full size
Aninhando estilos nas mensagens usando o chalk
Para finalizar, vamos dar uma olhada em como é fácil criar suas próprias regras de estilo usando a API do chalk.
Estilizando com o seu estilo
Podemos criar nossas próprias regras usando a API do chalk de forma muito prática. Primeiro vou expor um exemplo e então exploramos o que cada linha está fazendo.
const error = chalk.bold.red;
const warning = chalk.bold.keyword('orange');console.log(error("Algo errado não está certo!"));
console.log(warning("Não está errado mas também não está certo!"));
Aqui criamos dois estilos, error e warning . O primeiro, deixa a mensagem em negrito e vermelha. A segunda deixa a mensagem em negrito e com a cor laranja.
Na hora de exibir as mensagens, basta usarmos as palavras-chave criadas para os estilos! Veja só o resultado:
Press enter or click to view image in full size
Criando estilos próprios usando o chalk
Divertido e prático, não?
Código-fonte
Para quem quiser fazer os testes sem ter que ficar copiando do artigo, segue o código-fonte:
const chalk = require("chalk");
const msg = chalk.green("Hello World!");
const msg2 = chalk.red.bold("Hello World!");
const msg3 = chalk.bold(chalk.red("Hello ") + chalk.green("World"));
console.log(msg);
console.log(msg2);
console.log(msg3);
const error = chalk.bold.red;
const warning = chalk.bold.keyword('orange');
console.log(error("Algo errado não está certo!"));
console.log(warning("Não está errado mas também não está certo!"));
Conclusão
O chalk não é nenhuma biblioteca super revolucionária e pode parecer inútil para muitos, no entanto, se você for um usuário apaixonado pelo Console e o utiliza com frequência, não há dúvidas de que vale a pena dar uma olhada.
O avanço do código aberto e da IA visual está redefinindo quem pode criar, automatizar e inovar, de grandes empresas a profissionais independentes
Reprodução/Freepik
Nos últimos meses, venho observando um movimento que está transformando a maneira como desenvolvemos, conectamos e escalamos soluções digitais. Segundo dados recentes, 63% das empresas já fazem uso regular de modelos de IA de código aberto.
Durante muito tempo, falar em automação significava lidar com sistemas caros, integrações complexas e pouca flexibilidade. Era um território dominado por grandes corporações, onde a inovação dependia de licenças e contratos.
Mas o cenário mudou. O avanço do open source está liberando o poder da automação para profissionais de todos os perfis, incluindo desenvolvedores, criadores independentes e pequenas empresas que buscam eficiência sem abrir mão da autonomia.
Hoje, ferramentas como o n8n representam o que há de mais prático nesse novo ecossistema. Elas permitem construir fluxos de trabalho conectando aplicativos, APIs e serviços de IA em poucos cliques.
Um dentista pode automatizar agendamentos, um personal trainer pode integrar pagamentos e atendimento pelo WhatsApp, e uma startup pode escalar processos de marketing sem precisar ampliar a equipe.
O open source está aproximando pessoas com diferentes níveis de conhecimento e incentivando a experimentação. É um movimento coletivo que redefine o que significa inovar com propósito e simplicidade.
O novo poder da automação
O open source mudou completamente o terreno de jogo. Antes, automação era sinônimo de custo, dependência e restrição. Agora, tornou-se um campo aberto, colaborativo e acessível.
Você pode usar, adaptar e até contribuir com o código de uma ferramenta. Essa liberdade cria um ciclo virtuoso: quanto mais pessoas colaboram, mais forte e útil o ecossistema se torna. Essa cultura está acelerando o ritmo da inovação e permitindo que mais negócios explorem a automação.
Alguns dos impactos mais claros desse movimento incluem:
Redução de custos operacionais: licenças e assinaturas dão lugar a infraestrutura própria e controle de gastos.
Autonomia técnica: profissionais podem adaptar ferramentas ao seu fluxo de trabalho sem depender de fornecedores.
Colaboração global: comunidades abertas resolvem problemas juntos e compartilham soluções de forma contínua.
Maior transparência e segurança: o código aberto permite auditoria e confiança na execução dos processos.
O que mais me chama atenção é o ritmo de evolução dessas ferramentas. Em comunidades open source, um recurso lançado hoje pode ser aprimorado por dezenas de desenvolvedores em poucos dias.
Essa velocidade é algo que soluções proprietárias dificilmente conseguem acompanhar. No fim, ganha quem está disposto a aprender, compartilhar e evoluir junto.
O encontro entre IA e automação
A fusão entre IA generativa e automação open source está redefinindo papéis dentro das equipes. Surge uma nova figura: o maker automatizado, alguém que combina criatividade, curiosidade e ferramentas acessíveis para resolver problemas com eficiência.
Com o apoio de soluções como n8n e modelos de linguagem abertos, é possível construir assistentes inteligentes, fluxos de suporte automatizados e integrações complexas com pouco código. Essa combinação reduz tarefas repetitivas e libera tempo para criar novas experiências digitais.
Essa união também abre espaço para novas formas de trabalho. Profissionais de diversas áreas estão usando essas ferramentas para criar sistemas que respondem de forma inteligente e personalizada.
O que antes exigia um time técnico agora pode ser desenvolvido por pessoas com visão de negócio e disposição para aprender. Isso tem mudado a forma como as empresas inovam e, principalmente, como elas entregam valor para seus públicos.
O resultado é um ambiente de trabalho mais estratégico. Em vez de substituir o papel humano, a automação amplia sua capacidade. Ela transforma o desenvolvedor em um orquestrador de sistemas e o empreendedor em alguém capaz de validar soluções com velocidade.
O futuro do “maker automatizado”
Estamos vivendo uma fase em que o acesso à tecnologia está mais equilibrado. O conhecimento técnico ainda é valioso, mas não é mais um bloqueio para quem deseja inovar.
O maker automatizado representa essa nova geração de criadores que enxergam a automação como uma parceira de trabalho. Ele não substitui a expertise humana, mas a potencializa.
A próxima fronteira será a colaboração entre makers e especialistas. Desenvolvedores, designers e profissionais de negócios vão trabalhar lado a lado em plataformas abertas, construindo soluções mais rápidas, seguras e personalizadas.
O impacto disso vai além da produtividade: estamos falando de um novo modelo de criação, mais inclusivo e sustentável.
O open source é, acima de tudo, uma forma de reaproximar as pessoas da tecnologia. Ao tirar a complexidade do caminho, ela permite que a inovação seja mais distribuída, mais humana e mais conectada ao que realmente importa: resolver problemas de forma inteligente.
Em uma era dominada por notificações incessantes e feeds infinitos, a inteligência artificial opera uma revolução silenciosa na palma das nossas mãos. E essa sinergia entre smartphones e IA está democratizando o acesso à informação e ao conhecimento como nunca antes visto.
Com assistentes virtuais inteligentes, um universo de possibilidades se abre a um toque. Seja para obter respostas instantâneas para qualquer pergunta, aprender novos idiomas ou para explorar conteúdos educativos. São infinitas as possibilidades que encontramos nessa integração. Entretanto, a verdadeira revolução da IA nos smartphones transcende a mera adição de recursos tecnológicos ao aparelho.
Estamos diante de uma mudança de paradigma no acesso à tecnologia e suas implicações na sociedade que geram democratização, personalização, experiência do usuário, empoderamento individual, avanços em acessibilidade, impulsiona a inovação e gera impacto social em áreas estratégicas.
Para mim, carregar a IA em nossos bolsos é algo muito promissor para empoderar indivíduos e transformar vidas de maneiras que estamos apenas começando a descobrir. E isso é mais que uma tendência tecnológica, é um movimento disruptivo com o potencial de transformar a educação como a conhecemos. À medida que as barreiras de acesso à informação se dissolvem, abrimos espaço para uma sociedade mais informada, crítica e empoderada pelo conhecimento, preparada para um futuro moldado pela inteligência artificial.
No campo da educação, por exemplo, imagine um estudante com dificuldades em interpretar um diagrama complexo de física ou um mapa geográfico. Com a IA multimodal, ele pode capturar uma imagem com seu smartphone e pedir para que ela explique o conteúdo visual em detalhes, traduzindo o abstrato em concreto, o complexo em algo compreensível. Esse processo intuitivo e interativo quebra barreiras tradicionais de aprendizado, tornando a informação acessível a pessoas com diferentes estilos de aprendizagem e necessidades específicas e eliminando o problema de “ter vergonha” ao fazer uma pergunta.
O futuro da interação humano-IA traz profundas implicações para a educação. A câmera do nosso smartphone se transformará em um portal para a inteligência artificial, oferecendo suporte instantâneo para diversas necessidades. Como resolver problemas de matemática, traduzir textos em tempo real ou receber explicações detalhadas de conceitos complexos, tudo por meio de uma conversa contínua com a IA. Essa “tutoria on-demand” abre portas para um futuro promissor, onde o aprendizado se torna mais acessível, personalizado e interativo.
Dois exemplos claros dessa nova realidade são o ChatGPT, impulsionado pelo modelo GPT-4o, e o Gemini do Google, que já estão disponíveis via aplicativo em dispositivos móveis e, em breve, estarão rodando localmente nos smartphones, sem necessidade de acesso à internet. O ChatGPT atualmente vai além, liberando seu melhor modelo seja para usuários gratuitos ou assinantes.
O acesso ao poder de processamento e à vasta base de conhecimento da ferramenta é democratizado, nivelando o campo de jogo no acesso à informação. Em breve, novas funcionalidades, como o reconhecimento visual em tempo real através da câmera, transformarão ainda mais esse jogo. Essa acessibilidade universal é um divisor de águas, abrindo um leque de oportunidades para aprendizado personalizado e independente, livre de barreiras geográficas ou financeiras.
A inclusão é outro aspecto crucial dessa transformação. Pessoas com deficiência visual, por exemplo, já vivenciam uma nova realidade com os modelos de IA multimodais, capazes de descrever imagens e vídeos, traduzindo o visual em informações acessíveis. Essa capacidade de transpor barreiras sensoriais demonstra o potencial da IA para a construção de um futuro mais equitativo e inclusivo.
Tudo isso representa um potencial para empoderar indivíduos como nunca antes. E essa tendência está se acelerando rapidamente. Segundo projeções da Counterpoint, 43% dos aparelhos serão considerados smartphones GenAI até 2027, ano em que o número dos aparelhos deve superar a barreira do bilhão pela primeira vez.
E tudo isso é muito promissor. A experiência personalizada e intuitiva, a automatização de tarefas, a otimização do tempo, os avanços em acessibilidade e inclusão digital, além dos recursos inovadores em fotografia e realidade aumentada, convergem para empoderar o indivíduo e romper barreiras socioeconômicas.
É inegável que a IA nos celulares oferece um potencial transformador. No entanto, como toda tecnologia disruptiva, sua integração traz consigo desafios e dilemas éticos que exigem atenção. Embora seja crucial estarmos conscientes dos desafios, os benefícios da inteligência artificial nos dispositivos móveis têm um potencial transformador inegável, capaz de impulsionar o progresso humano em diversas áreas.
Cabe à sociedade, como um todo, participar ativamente do debate sobre o desenvolvimento e a utilização responsável da IA, garantindo que essa poderosa ferramenta seja utilizada para o bem comum. Afinal, estamos falando de uma revolução que já está acontecendo, agora, na palma de nossas mãos.
Na semana passada tive o privilégio de participar de um painel da edição paulistana de DevDay Exchange São Paulo — a versão local do evento global OpenAI DevDay — e, como alguém que acompanha o mercado de tecnologia há muitos anos, saio com muitas reflexões: sobre o evento em sua forma “origem” nos EUA, sobre o que ele representa para o setor de IA e, especialmente, sobre o que isso significa para nós, desenvolvedores brasileiros.
A origem: OpenAI DevDay nos EUA
O DevDay da OpenAI nasceu como a grande conferência anual da empresa para desenvolvedores — foi lá em San Francisco que, em 6 de outubro de 2025, a OpenAI lançou o que chamou de sua “maior DevDay até agora”.
No evento norte-americano, os participantes assistem a keynotes com os executivos de topo, sessões técnicas profundas, demonstrações ao vivo de novos modelos, ferramentas para desenvolvimento de agentes, integração multimodal, etc.
É um momento em que a empresa revela sua agenda para o ano seguinte — o que vai liberar de API, que modelos entram em produção, qual será sua estratégia de plataformas e ecossistema de parceiros. Por exemplo: no DevDay 2025 foram anunciados modelos como o “Sora 2”, o “gpt-realtime-mini”, o kit de agentes “AgentKit”, entre outros.
Para o setor, isso representa o “momento de alinhamento” — quando todos olham para onde a OpenAI está apontando, e começam a calibrar suas apostas de produto, de arquitetura, de estratégia de IA.
O que o evento representa para o setor tecnológico
Participar ou acompanhar o DevDay (nos EUA ou nas variantes regionais) significa alguns impactos importantes:
Definição de rumo: quando a OpenAI mostra novas ferramentas, ela impacta não só quem já é “early adopter”, mas também quem está planejando entrar no ecossistema. Ver onde as APIs vão, quais modelos virão, ajuda a decidir “onde investir” em pesquisa, produto ou equipe.
Ecossistema em movimento: não é só sobre modelos — é sobre plataformas, integração, agentes autônomos, recursos multimodais. Isso muda o jogo para empresas de software, para startups, para times de devs. Por exemplo, a noção de “app dentro do ChatGPT” já aparece como nova fronteira.
Competição e colaboração global: vimos no evento que a OpenAI está enfrentando concorrentes fortes (como Google, Anthropic) e, ao mesmo tempo, buscando parcerias, formas de escalar, de democratizar acesso.
Mudança de mindset para desenvolvedores: quem vai ao DevDay volta com “idéias maiores”: não simplesmente “usar um modelo para preencher X”, mas “como criar agentes, como construir workflows, como projetar comportamento de IA, como gerar valor real com IA”. A técnica de “prompt + modelo” ainda é importante, mas o evento empurra para “arquitetura de agente + modelo + integração”.
O que significa para os desenvolvedores brasileiros
E aqui é onde a edição de São Paulo assume um papel especial — e sou grato por ter participado.
Acesso local: nem todo dev ou startup no Brasil tem condição de voar para San Francisco, fazer o evento em inglês, absorver tudo. A versão aqui permite “ver de perto” o que está acontecendo globalmente, com contexto local, com networking em português, com trocas que fazem sentido para o mercado brasileiro.
Adaptação ao mercado local: o Brasil tem particularidades — idioma, cultura de produto, modelo de negócio, infraestrutura. Ver como os lançamentos globais se inserem no nosso contexto ajuda a calibrar “o que faz sentido aqui”. Por exemplo: se uma API exige uma infraestrutura de latência baixa ou consumos de tokens altos, como isso pesa em empresas brasileiras?
Incentivo à construção de ecossistema: participar desse tipo de evento mostra que “não somos periféricos”. O Brasil está dentro da rota global de IA, e isso abre oportunidades para parcerias, projetos, inclusive de visibilidade internacional. Para devs, isso significa “estamos na rede”.
Desenvolver com ambição: estar num DevDay abre o horizonte. Percebi ontem em São Paulo que vários participantes já estavam pensando “e se a gente construir um agente para X?”, “e se a gente usar isso para produto Y?”. Ou seja: o nível de ambição sobe.
Rede de contatos e inspiração: além das palestras, a troca de ideias, os “hallways”, os workshops — tudo isso gera inspiração. Que tipo de aplicação de IA eu posso fazer hoje, com as ferramentas que a OpenAI já liberou? Que dúvida técnica ainda tenho? Que parceria posso buscar? Essas respostas fluem mais facilmente quando se está num evento.
Minhas principais reflexões após o evento em São Paulo
* Vi mais claramente que IA de produção está deixando de ser “experimento” para virar “produto”. Os kits de agente, as ferramentas para automação, mostram que agora o foco é: “Como vou colocar isso em funcionamento real?”
* A barreira entre “modelo de IA” e “logic workflow / agente autônomo” está se estreitando. Ou seja: não basta ter o modelo, é preciso ter “o que fazer com ele”. E isso muda o perfil do dev.
* No Brasil, temos uma janela de oportunidade: muitos players ainda não estão totalmente atentos às mudanças rápidas que um DevDay sinaliza. Quem absorver essas mudanças mais cedo pode ganhar vantagem.
* Ao mesmo tempo: ajuste de expectativas. As ferramentas são poderosas, mas não são “plug & play perfeito” em todos os contextos. Latência, custo, tokenização, integração… são fatores que aqui importam mais.
* Para mim, ficou claro que este tipo de evento favorabiliza quem está disposto a mudar, aprender e experimentar. Se você for “continuar com o mesmo pipeline de sempre”, talvez não aproveite tanto. Mas se quiser repensar arquitetura, produto, integração de IA — esse é o momento.
Conexão
Participar da edição de São Paulo do DevDay Exchange foi mais do que “assistir a palestras”: foi conectar global + local, compreender “o que vem pela frente” da OpenAI e refletir como nós, no Brasil, podemos entrar nessa próxima onda de IA com mais preparo.
Para os desenvolvedores brasileiros, meu convite é simples: leve isso como um chamado para agir. Inspecione o que foi anunciado, projete o que pode caber no seu produto, experimente. Se o evento global define a rota, nós precisamos estar prontos para embarcar.
Você sempre quis contribuir para um projeto open source? Então deixa eu te explicar como eu adicionei meu código no Node.js!
Há um pouco mais de um ano, eu tive o grande prazer de trabalhar no core do Node.js, e foi uma das experiências mais interessantes que eu já tive (então se você tá usando Node hoje, tem código meu ai!), tanto que agora estou voltando a trabalhar e ajudar a comunidade a crescer em volta dele também, porém, o que eu quero te contar aqui é como funcionam os Date mocks dentro do Node Test Runner, parte a parte!
O objetivo desse artigo é tanto documentar o que foi feito nesta funcionalidade, mas também mostrar como não é tão complexo entender o código open source que temos por ai, e que você também pode contribuir para o projeto que mais curte.
O objetivo
Tudo isso é muito bonito, mas o que são os mocks e para que a gente usaria algo assim?
Eu não vou entrar no conceito do que são mocks aqui em detalhe, mas você pode entender mais sobre eles nesse artigo (antigo, porém relevante)
Eu queria poder fazer algo assim:
import assert from 'node:assert';
import { test } from 'node:test';
test('mocks Date.now to whatever value the user sets', (context) => {
const now = Date.now()
console.log(now) // data atual, o tempo continua correndo
// iniciamos os mocks
context.mock.timers.enable({ apis: ['Date'] });
// agora a data está fixa em 1000ms depois da época inicial
context.mock.timers.setTime(1000)
assert.strictEqual(Date.now(), 1000) // true
});
Praticamente, mocks de datas são muito utilizados para testar funcionalidades que são sensíveis a tempo, por exemplo, uma rotina ou cronjob que rodaria depois de X dias de um evento. Isso era muito comum na Klarna (e também é na maioria das empresas) quando tínhamos que lidar com ciclos de vida de cartões de crédito, então, por exemplo, a cada dia temos que pegar os cartões que venceram há 30 dias e rodar algum processo. Como se testa isso? Substituindo a data do computador pela sua própria, fazendo o Node pensar que ele está em uma data específica.
Graças à natureza dinâmica do JavaScript, isso não é tão complexo, mas eu descobri que você tem que conhecer bem a fundo a especificação para poder entender as consequências do que você pode fazer.
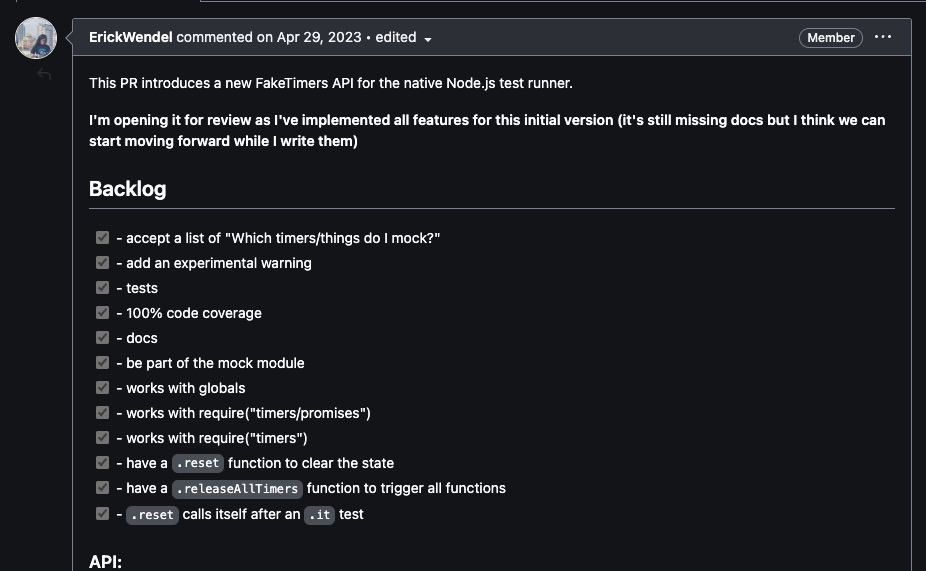
O começo
Para a gente entender mais como funcionam os mocks, a gente precisa voltar um pouco para algumas PRs anteriores. O trabalho na minha PR começou com uma dica de um grande amigo, Erick Wendel, que tinha feito uma PR alguns meses antes implementando os mocks para os timers (setTimeout, setInterval e etc).
a PR original do Erick
Quando eu comecei a usar o test runner nos meus projetos, logo eu já tive um grande problema: por mais que a gente pudesse fazer mocks de timers, eu não conseguia fazer mocks de datas! Ou seja, eu não podia resetar o relógio do meu teste e controlar como eu queria que ele se comportasse… Algo precisava ser feito.
Eu sugeri essa ideia para o pessoal antes (poderia ter simplesmente feito, mas resolvi primeiro perguntar) e a maioria da galera gostou. Como outros test runners (Jest, Ava, Vitest, mocha, jasmine…) já tinham essa funcionalidade, seria interessante também tê-la implementada no NTR, isso traria mais adoção a plataforma.
O planejamento
A ideia é que os mocks de datas se comportassem bem parecidos com a implementação do Sinon, que também é a implementação usada no Jest, então significa que é uma API já conhecida da galera.
Eu comecei a pesquisar quais seriam os métodos principais e como eu poderia integrar essa nova API na API já existente de mocks e cheguei a conclusão que seria mais fácil implementar somente o método now da data, que era mais simples e poderia ser mais útil, essa era a versão inicial da minha PR:
Perceba que eu já estava pensando que talvez fosse melhor mockar todo o objeto de data, e não só o now, o que é consideravelmente mais complexo do que só o módulo.
Eu não vou ir passo a passo do que eu fiz aqui, mas o contexto inicial é importante para entender as decisões futuras.
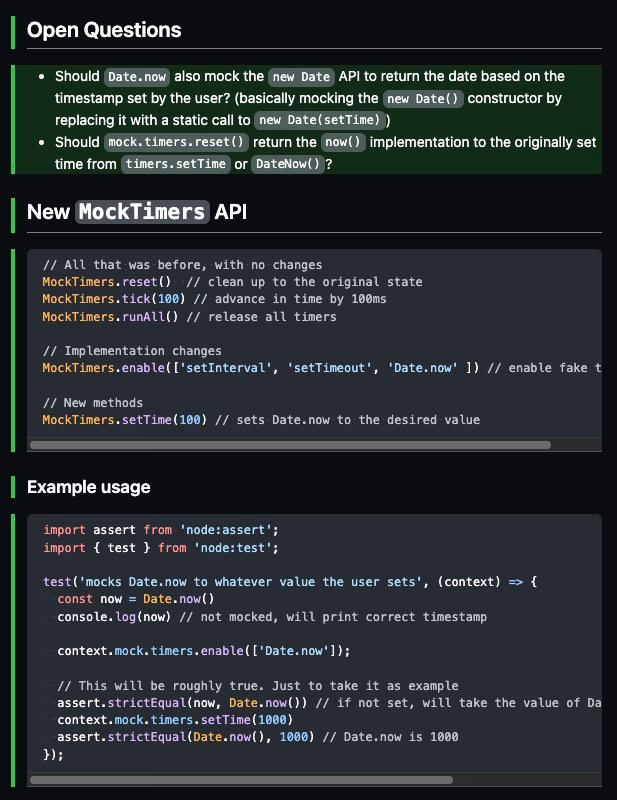
No final, depois de muitos comentários, a integração com a API de timers criada antes pelo Erick ficou assim:
// Tudo que a API já tinha antes
MockTimers.reset()
MockTimers.tick(100)
MockTimers.runAll()
// Implementações que foram alteradas
MockTimers.enable({ timersToEnable: ['setInterval', 'setTimeout', 'Date' ], now: 1000 })
// Novos métodos
MockTimers.setTime(100)
Eu iria manter o principal uso, já que ela já estava em produção, mas modificar o parâmetro de MockTimers.enable que antes era um array de strings, para um objeto, porque agora poderíamos passar configurações para as datas.
Além disso, o MockTimers teria um novo método setTime, que iria alterar a data no mock. Mas, como é de costume no Node, os parâmetros iniciais da maioria das APIs são opcionais, então eu modifiquei a ideia para que ele também funcionasse assim:
MockTimers.enable({ now: 1000 }) // sem uma lista, iriamos mockar todos os métodos
// ou
MockTimers.enable() // começa com a época 0
Com a API inicial decidida, vem a questão principal: Como eu consigo mockar uma das principais APIs da linguagem sem quebrar nada?
O código
Por incrível que pareça, toda a adição do date mock no Node foi feita em um único arquivo chamado mock_timers.js dentro de lib/internal/test_runner/mock. Isso é uma prática bastante comum em projetos mais antigos e estabelecidos porque faz com que PRs sejam bem menores já que o arquivo é grande mas tem todas as alterações necessárias.
Houve uma pequena alteração em outro arquivo, mas isso eu vou falar mais tarde.
Quando eu comecei a codar essa funcionalidade eu pensei: “Mas como raios eu crio um mock”, na real é bem simples, um mock nada mais é do que um objeto com uma interface idêntica ao objeto original, mas com o comportamento diferente. Então, por exemplo, se você quisesse manualmente fazer um mock do método now do Date, basta você fazer algo assim:
Claro que um método não é um objeto, então como fazemos isso? Primeiro, temos que criar as nossas propriedades novas, no caso é a data inicial, que vai ser 0, que é a uma propriedade privada chamada #now:
//https://github.com/nodejs/node/blob/bb7fc653e9199c5b65a7ed268f9e827d049d7a81/lib/internal/test_runner/mock/mock_timers.js#L123
class MockTimers {
// ... inicio do código aqui
#now = kInitialEpoch;
}
kInitialEpoch é uma constante (por isso que começa com k) definida na linha 50 como 0.
Constantes como essa são muito comuns no core do Node, principalmente quando são usadas com Symbols, já que temos que garantir propriedades não enumeráveis internas, vamos ver mais sobre isso aqui.
Além dessa propriedade, como fizemos no nosso mock manual, temos que salvar o método original, dentro do MockTimers, o Node já faz isso com várias outras propriedades privadas:
Elas estão aqui porque, quando chamamos o reset, esses mocks precisam deixar de existir, ou seja, temos que atualizá-los pelos métodos originais. Então todo o MockTimers nada mais é do que uma classe que troca globalThis.<seu objeto> por um mock idêntico e guarda o valor original até você mandar ele recuperar. Agora as coisas ficaram mais simples.
Vamos adicionar uma outra propriedade ali que será o descritor do objeto Date:
//https://github.com/nodejs/node/blob/bb7fc653e9199c5b65a7ed268f9e827d049d7a81/lib/internal/test_runner/mock/mock_timers.js#L118
class MockTimers {
// ... inicio do código aqui
#nativeDateDescriptor // L118
#now = kInitialEpoch; // L123
}
JavaScript
💡
É importante notar que Date não é uma função, então a gente não pode armazenar só o valor dele, como ele é um objeto, o JavaScript vai passar essa variável por referência, então temos que armazenar o descritor que pegamos com Object.getOwnPropertyDescriptor
Quando comecei a ver a forma que os timeouts estavam implementados, eu tive uma ideia. Hoje eles estão sendo criados cada um por uma função, dessa forma:
Um detalhe importante é que o Node não pode usar os primordiais (como umaFuncao.bind(this) diretamente, já que isso é implementado pelo engine. Então existem funções internas que vão diretamente na raiz de onde esses métodos são executados (lá no V8) e fazem a mesma coisa, porém com um nome diferente, então o bind seria FunctionPrototypeBind, mas a ideia é a mesma
Então eu iria seguir o mesmo padrão, e é aí que a nossa história começa.
É só uma função
A nossa função que cria um objeto de data é relativamente simples:
Criamos dois objetos iniciais, o primeiro vai ser uma constante associada a um Symbol que vai representar o objeto de mocks como um todo, a gente vai precisar disso mais pra frente porque precisamos retornar o timestamp atual quando ela não é usada como um construtor (tipo Date(), lembra?), porque a gente precisa acessar as propriedades que o usuário definiu, como o kInitialEpoch. Essa propriedade aparece bem no início, mas ela só vai ser usada lá no final da nossa função.
A segunda é o construtor nativo do Date sem mudanças, porque a gente vai ter que retornar algumas funções que não precisam de mocks, por exemplo toString.
Logo depois vamos criar uma função dentro dessa função, a ideia é que a gente possa criar nosso objeto de mock dentro dessa função e retorná-la para o usuário, a gente só faz isso porque ele precisa ser capaz de criar a data como uma instância com new Date, e isso só é possível se a gente cria uma classe ou uma função, além disso, closures como essa permitem que a gente encapsule o nosso código interno dos mocks deixando ele privado:
Dentro dela a gente já puxa a nossa constante nova que foi definida lá em cima e cria um objeto com o valor dele.
Toda essa parte sobre o Symbol e o kMock vai ser explicada em uma seção a parte mais pra frente, então não precisa se preocupar em entender aqui.
Vamos tratar já o primeiro e único caso de uso diferente que temos, quando a gente chama a propriedade estática now, ou seja, a data não é uma instância, e a gente precisa conseguir identificar isso.
🥵
Essa foi uma das partes mais difíceis de programar nesse código porque é um tipo de meta programação onde estamos olhando para a propriedade de um objeto como se fossemos o agente externo, ou seja, o próprio objeto tem que saber se ele foi chamado como uma instância ou como um método estático
Eu olhei bastante a implementação do Sinon pra isso, juntamente com duas partes da spec do ECMA, primeiro o ECMA 262 edicão 5.2 – Seção 15.9.2 que basicamente descreve o comportamento quando a gente chama a função como Date(), ela precisa retornar a data completa por extenso em UTC
Ótimo, mas como eu sei que ela foi chamada como uma função? Podemos usar if (!(this instanceof MockDate)), certo? Isso deve funcionar porque se a data não for uma instância do nosso objeto de mock, ela então é uma função, que é a única outra forma de chamada, daí é só a gente implementar o nosso resultado, que é a data como string:
O que queremos fazer é só retornar a data real como uma string, mas em uma época específica, a época que definimos como inicial ou o now que o usuário passa no mock, por isso que precisamos do kMock e também do NativeDateConstructor, dessa forma a gente pode pegar o objeto REAL de data e construir ele como se fosse new Date(Date.now()), e ai pegar a representação como string.
Pena que isso não funciona. Por vários motivos, dentro da nossa função vamos ter um grande problema com this porque ele vai entrar em um estado inconsistente, mas o mais gritante disso é que instanceofnão é confiável. A gente pode falsificar a instância de um objeto se a gente substituir o prototype dele pelo que a gente quiser.
Na verdade esse é um de mais de uma dúzia de comentários onde a gente só discute isso. E também foi o último problema que eu resolvi antes de fazer o merge do código, mesmo sendo a primeira coisa que a função faz.
Depois de pesquisar MUITO eu achei uma outra parte da especificação mais recente (edição 14 seção 21.4.2.1) que diz mais ou menos como ela deve ser implementada:
A versão 5.2 e a versão 14.0 da especificação são extensões uma da outra, a versão 14 é a mais nova de 2023 enquanto a 5.2 é bem antiga. Por conta disso todas as especificações da 5.2 mudaram de lugar, mas todo o conteúdo da 5.2 existe na 14.
Aqui temos uma pista do que fazer. O que é o NewTarget? Ele é justamente uma propriedade nativa de qualquer função ou classe que permite que a gente saiba o contexto de execução de tal objeto, ele é representado como new.target, ou seja, é o objeto que está na frente da keyword new. Quando a gente chama o Date como new Date o new.target vai ser um construtor de Date, já quando a gente executa Date() como uma função, new.target é undefined porque não existe um new para ter um target (documentação aqui). Então agora é simples, vamos só substituir nosso instanceof:
Daqui para frente a implementação fica consideravelmente mais simples. O próximo passo é saber qual das 11 formas de chamar o date estamos usando, para isso eu simplesmente copiei a implementação do Sinon para isso e fiz algumas modificações:
#createDate() { // L279
kMock ??= Symbol('MockTimers');
const NativeDateConstructor = this.#nativeDateDescriptor.value;
// Nossa função que será o mock
function MockDate(year, month, date, hours, minutes, seconds, ms) {
const mockTimersSource = MockDate[kMock];
const nativeDate = mockTimersSource.#nativeDateDescriptor.value;
if (!(this instanceof MockDate)) {
return DatePrototypeToString(new nativeDate(mockTimersSource.#now))
}
switch (arguments.length) {
case 0:
return new nativeDate(MockDate[kMock].#now);
case 1:
return new nativeDate(year);
case 2:
return new nativeDate(year, month);
case 3:
return new nativeDate(year, month, date);
case 4:
return new nativeDate(year, month, date, hours);
case 5:
return new nativeDate(year, month, date, hours, minutes);
case 6:
return new nativeDate(year, month, date, hours, minutes, seconds);
default:
return new nativeDate(year, month, date, hours, minutes, seconds, ms);
}
}
}
Lembrando que a gente tem que contar a quantidade de argumentos e que eles são todos posicionais e a gente só precisa tratar os argumentos específicos, porque se o usuário está passando uma data específica para a gente, não precisamos retornar a data que ele colocou, já que ele está criando um novo objeto, portanto, quando temos 1 argumento, ele vale tanto para quando criarmos um objeto de um objeto como new Date(new Date()), ou uma string new Date('2024-05-10') e qualquer outro, porque estamos delegando para a data original a execução dessa função.
Agora que já terminamos a nossa função MockDate, temos que definir todas as propriedades extras que o Date tem (toString, toISOString, etc) porque elas vão se manter iguais e eu não quero ter que implementar tudo na mão. Porém o nosso objeto de data não pode substituir o protótipo do nosso objeto atual, por isso vamos remover o protótipo e associar somente as propriedades:
#createDate() { // L279
kMock ??= Symbol('MockTimers');
const NativeDateConstructor = this.#nativeDateDescriptor.value;
// Nossa função que será o mock
function MockDate(year, month, date, hours, minutes, seconds, ms) {
const mockTimersSource = MockDate[kMock];
const nativeDate = mockTimersSource.#nativeDateDescriptor.value;
if (!(this instanceof MockDate)) {
return DatePrototypeToString(new nativeDate(mockTimersSource.#now))
}
switch (arguments.length) {
case 0:
return new nativeDate(MockDate[kMock].#now);
case 1:
return new nativeDate(year);
case 2:
return new nativeDate(year, month);
case 3:
return new nativeDate(year, month, date);
case 4:
return new nativeDate(year, month, date, hours);
case 5:
return new nativeDate(year, month, date, hours, minutes);
case 6:
return new nativeDate(year, month, date, hours, minutes, seconds);
default:
return new nativeDate(year, month, date, hours, minutes, seconds, ms);
}
}
// removemos o protótipo
const { prototype, ...dateProps } = ObjectGetOwnPropertyDescriptors(NativeDateConstructor);
// associamos as propriedades
ObjectDefineProperties(MockDate, dateProps);
}
O único método que temos que substituir é o now que tem sempre que retornar o que o usuário colocou no mock, mas isso é bastante simples porque now é um método estático então podemos simplesmente fazer MockDate.now = ...:
#createDate() { // L279
kMock ??= Symbol('MockTimers');
const NativeDateConstructor = this.#nativeDateDescriptor.value;
// Nossa função que será o mock
function MockDate(year, month, date, hours, minutes, seconds, ms) {
const mockTimersSource = MockDate[kMock];
const nativeDate = mockTimersSource.#nativeDateDescriptor.value;
if (!(this instanceof MockDate)) {
return DatePrototypeToString(new nativeDate(mockTimersSource.#now))
}
switch (arguments.length) {
case 0:
return new nativeDate(MockDate[kMock].#now);
case 1:
return new nativeDate(year);
case 2:
return new nativeDate(year, month);
case 3:
return new nativeDate(year, month, date);
case 4:
return new nativeDate(year, month, date, hours);
case 5:
return new nativeDate(year, month, date, hours, minutes);
case 6:
return new nativeDate(year, month, date, hours, minutes, seconds);
default:
return new nativeDate(year, month, date, hours, minutes, seconds, ms);
}
}
// removemos o protótipo
const { prototype, ...dateProps } = ObjectGetOwnPropertyDescriptors(NativeDateConstructor);
// associamos as propriedades
ObjectDefineProperties(MockDate, dateProps);
// mantém o this correto dentro da função
MockDate.now = function now() {
return MockDate[kMock].#now
}
}
O próximo passo é uma pequena alteração para evitar que, quando você fizer Date.toString(), você receba o código real nativo que é 'function Date() { [native code] }', e não a implementação do nosso código de Mock, lembre-se ela precisa ser INDISTINGUÍVEL de um Date. Pra isso a gente sobrescreve a função toString com o código original:
#createDate() { // L279
kMock ??= Symbol('MockTimers');
const NativeDateConstructor = this.#nativeDateDescriptor.value;
// Nossa função que será o mock
function MockDate(year, month, date, hours, minutes, seconds, ms) {
const mockTimersSource = MockDate[kMock];
const nativeDate = mockTimersSource.#nativeDateDescriptor.value;
if (!(this instanceof MockDate)) {
return DatePrototypeToString(new nativeDate(mockTimersSource.#now))
}
switch (arguments.length) {
case 0:
return new nativeDate(MockDate[kMock].#now);
case 1:
return new nativeDate(year);
case 2:
return new nativeDate(year, month);
case 3:
return new nativeDate(year, month, date);
case 4:
return new nativeDate(year, month, date, hours);
case 5:
return new nativeDate(year, month, date, hours, minutes);
case 6:
return new nativeDate(year, month, date, hours, minutes, seconds);
default:
return new nativeDate(year, month, date, hours, minutes, seconds, ms);
}
}
// removemos o protótipo
const { prototype, ...dateProps } = ObjectGetOwnPropertyDescriptors(NativeDateConstructor);
// associamos as propriedades
ObjectDefineProperties(MockDate, dateProps);
// mantém o this correto dentro da função
MockDate.now = function now() {
return MockDate[kMock].#now
}
MockDate.toString = function toString() {
return FunctionPrototypeToString(MockDate[kMock].#nativeDateDescriptor.value);
};
}
Estamos chegando no fim, o que a gente precisa fazer agora é definir a única propriedade que já usamos bastante mas ainda não foi definida, o kMock, você chegou a perceber isso?
kMock
O kMock é um símbolo dentro da nossa implementação que, basicamente, é uma referência ao nosso objeto geral de Mocks para que a gente possa pegar as propriedades privadas como #now e o construtor original da data. Mas ele não foi definido até agora, isso não vai dar um problema sério?
Na verdade não, porque sempre que chamamos o MockDate[kMock] estávamos dentro de uma função, e MockDate não vai existir até o final da nossa função #createDate, então é seguro que a gente defina ele só no final, até porque a gente precisa tanto do MockDate, quanto do símbolo para isso. A gente só definiu o símbolo lá em cima para segurar a referência que vamos usar, porque agora podemos fazer isso aqui:
O que estamos fazendo aqui são duas coisas, estamos pegando a nossa função MockDate e criando propriedades nela, primeiramente definindo o protótipo como nulo para evitar problemas de herança, e depois dizendo que [kMock] é outro objeto que não é enumerável, não é modificável e não pode ser configurado, ou seja, ele é totalmente imutável e está apontando para MockTimers, que é o this no contexto de #createDate.
Depois temos uma outra propriedade que é meu toque pessoal nesse código, uma forma de saber se essa data é uma instância de um mock chamando MockDaData.isMock, esse valor é enumerável porém não é alterável. Isso é necessário as vezes quando estamos lidando com testes que estão usando múltiplos mocks de data.
Até agora nossa função está assim:
#createDate() { // L279
kMock ??= Symbol('MockTimers');
const NativeDateConstructor = this.#nativeDateDescriptor.value;
// Nossa função que será o mock
function MockDate(year, month, date, hours, minutes, seconds, ms) {
const mockTimersSource = MockDate[kMock];
const nativeDate = mockTimersSource.#nativeDateDescriptor.value;
if (!(this instanceof MockDate)) {
return DatePrototypeToString(new nativeDate(mockTimersSource.#now))
}
switch (arguments.length) {
case 0:
return new nativeDate(MockDate[kMock].#now);
case 1:
return new nativeDate(year);
case 2:
return new nativeDate(year, month);
case 3:
return new nativeDate(year, month, date);
case 4:
return new nativeDate(year, month, date, hours);
case 5:
return new nativeDate(year, month, date, hours, minutes);
case 6:
return new nativeDate(year, month, date, hours, minutes, seconds);
default:
return new nativeDate(year, month, date, hours, minutes, seconds, ms);
}
}
// removemos o protótipo
const { prototype, ...dateProps } = ObjectGetOwnPropertyDescriptors(NativeDateConstructor);
// associamos as propriedades
ObjectDefineProperties(MockDate, dateProps);
// mantém o this correto dentro da função
MockDate.now = function now() {
return MockDate[kMock].#now
}
MockDate.toString = function toString() {
return FunctionPrototypeToString(MockDate[kMock].#nativeDateDescriptor.value);
};
ObjectDefineProperties(MockDate, {
__proto__: null,
[kMock]: {
__proto__: null,
enumerable: false,
configurable: false,
writable: false,
value: this,
},
isMock: {
__proto__: null,
enumerable: true,
configurable: false,
writable: false,
value: true,
},
});
}
Toques finais
O toque final é definir o protótipo da nossa MockDate para o protótipo original do Date, dessa forma não quebramos aplicações de quem está fazendo instanceof Date, além disso, definimos os métodos estáticos globais comuns que não vamos substituir e retornamos todo o nosso trabalho:
#createDate() { // L279
kMock ??= Symbol('MockTimers');
const NativeDateConstructor = this.#nativeDateDescriptor.value;
// Nossa função que será o mock
function MockDate(year, month, date, hours, minutes, seconds, ms) {
const mockTimersSource = MockDate[kMock];
const nativeDate = mockTimersSource.#nativeDateDescriptor.value;
if (!(this instanceof MockDate)) {
return DatePrototypeToString(new nativeDate(mockTimersSource.#now))
}
switch (arguments.length) {
case 0:
return new nativeDate(MockDate[kMock].#now);
case 1:
return new nativeDate(year);
case 2:
return new nativeDate(year, month);
case 3:
return new nativeDate(year, month, date);
case 4:
return new nativeDate(year, month, date, hours);
case 5:
return new nativeDate(year, month, date, hours, minutes);
case 6:
return new nativeDate(year, month, date, hours, minutes, seconds);
default:
return new nativeDate(year, month, date, hours, minutes, seconds, ms);
}
}
// removemos o protótipo
const { prototype, ...dateProps } = ObjectGetOwnPropertyDescriptors(NativeDateConstructor);
// associamos as propriedades
ObjectDefineProperties(MockDate, dateProps);
// mantém o this correto dentro da função
MockDate.now = function now() {
return MockDate[kMock].#now
}
MockDate.toString = function toString() {
return FunctionPrototypeToString(MockDate[kMock].#nativeDateDescriptor.value);
};
ObjectDefineProperties(MockDate, {
__proto__: null,
[kMock]: {
__proto__: null,
enumerable: false,
configurable: false,
writable: false,
value: this,
},
isMock: {
__proto__: null,
enumerable: true,
configurable: false,
writable: false,
value: true,
},
});
MockDate.prototype = NativeDateConstructor.prototype;
MockDate.parse = NativeDateConstructor.parse;
MockDate.UTC = NativeDateConstructor.UTC;
MockDate.prototype.toUTCString = NativeDateConstructor.prototype.toUTCString;
return MockDate;
}
Métodos do mock
Agora que temos o mock principal, podemos definir as outras funções que vem junto dele, primeiro temos que modificar o nosso método enable, para que ele também possa aceitar a nova API. A modificação que vamos fazer aqui é basicamente de validação:
// criamos o `now` como parâmetro nas opções
enable(options = { __proto__: null, apis: SUPPORTED_APIS, now: 0 }) {
// clonamos o objeto de options
const internalOptions = { __proto__: null, ...options };
// ... código original
// setamos o valor caso ele não exista
if (!internalOptions.now) {
internalOptions.now = 0;
}
// Se APIs não for passado, vamos ter todos habilitados
if (!internalOptions.apis) {
internalOptions.apis = SUPPORTED_APIS;
}
// ... Código original
// Now pode ser uma instancia de Date então checamos isso
if (this.#isValidDateWithGetTime(internalOptions.now)) {
this.#now = DatePrototypeGetTime(internalOptions.now);
}
// Caso contrário é um número
else if (validateNumber(internalOptions.now, 'initialTime') === undefined) {
this.#assertTimeArg(internalOptions.now);
this.#now = internalOptions.now;
}
this.#toggleEnableTimers(true);
}
A nossa função #isValidDateWithGetTime não checa realmente se é uma instância de Date, na verdade ele só checa se esse objeto tem uma propriedade getTime que é o que a gente precisa usar:
A nossa função #toggleEnableTimers é basicamente um objeto grande com duas propriedades: toFake e toReal, que contém as funções necessárias para que possamos converter o objeto em mock e de volta para o nativo:
O tick já existia, mas a gente tem que fazer uma pequena modificação. Esse método avança o tempo em um número determinado de milisegundos, então temos que avançar o #now também:
tick(time = 1) { // L613
// ... código de validação
this.#now += time;
// ... restante do código não modificado
}
O último método é o runAll que teve uma pequena alteração em outro arquivo. A ideia desse método é rodar todos os timers agendados, para isso a gente usa uma estrutura chamada de PriorityQueue, que é basicamente uma fila ordenada por tempo, ou seja, o timer com o menor timeout está no topo e o com maior timeout no final.
A PriorityQueue está definida no caminho lib/internal/priority_queue.js, ela continha já um método chamado peek que pega o primeiro item da fila sem tirar ele de lá, a gente precisa pegar o último, porque agora temos que saber qual é o timer que tem o maior tempo, subtrair do tempo que já passou (o nosso #now) e chamar o método tick com essa subtração, dessa forma vamos rodar todos os timers sem adicionar tempo a mais na nossa data (porque agora o tick está adicionando milissegundos no nosso #now), para isso eu criei um método chamado peekBottom.
Eu não vou colocar essa implementação da PriorityQueue aqui, mas o link acima vai te levar pra lá
A implementação em si é bem direta:
runAll() { // L728
this.#assertTimersAreEnabled();
const longestTimer = this.#executionQueue.peekBottom();
if (!longestTimer) return; // fila vazia
// Avança o tempo
this.tick(longestTimer.runAt - this.#now);
}
E acaba por ai?
Essa foi a final da implementação dos timers, mas o trabalho não acabou. Como o artigo está longo eu não vou postar muito mais sobre isso. Os testes para essa funcionalidade foram outro tempo a parte, no total devo ter gasto pelo menos 13 horas nesse projeto, além de uns 3 meses em comentários, resoluções e tudo mais. No final, essa funcionalidade foi implementada na versão 21.2 do Node (tem até um post explicando como usar).
Dá pra ver que eu estava bem feliz
Além disso, se você olhar no histórico da PR, vai ver que eu passei dias lutando com o CI do GitHub porque existiam os chamado flaky tests, que foram corrigidos pelo Yagiz um tempo depois.
Eu estava ficando maluco já
Esses flaky tests estavam impedindo que minha aplicação tivesse sinal verde, mas os erros não tinham nada a ver com o código que eu mudei. Por isso que é tão importante que contribuidores como nós possamos ajudar com a cobertura de testes e verificação do processo.
Conclusão
Foi um artigo longo, mas eu quis trazer esse conteúdo aqui porque eu quero mostrar para você que é sim possível participar de projetos open source grandes e fazer a diferença mesmo em pequenas contribuições como essa.
O processo de contribuir para um projeto grande é complexo, envolve muitas e muitas variáveis e muitos dias e semanas de conversa com todo mundo, mas é extremamente desafiador e recompensador quando tudo termina!
Espero que você tenha se sentido inspirado(a) a tentar contribuir para o Open Source!