
Se você criar alguma aplicação web pública, que receba um mínimo de atenção, é comum que você passe a ter problemas com bots. Principalmente se a sua aplicação fornece alguma vantagem ou ganho financeiro aos usuários ou ainda se a área logada dela é atrativa o bastante para alguém querer invadi-la. É certo que nestas situações algum hacker vai buscar automatizar a atividade de login ou de uso da aplicação, o que pode ser um risco de segurança grave ou ao menos um risco econômico.
Recentemente passei por isso em um projeto de faucet para uma nova criptomoeda e para evitar que os usuários automatizassem a emissão de tokens, optei por colocar um captcha, uma solução que já havia usado no passado para evitar bruteforce em telas de login e que veio a me ajudar novamente para evitar abusos no clique do meu único botão da aplicação.
Neste tutorial eu quero lhe ensinar como implementar este recurso também na sua aplicação.
#1 – O que é captcha?
Captcha é uma sigla para “Completely Automated Public Turing test to tell Computers and Humans Apart” ou “teste de Turing completamente automatizado para separar humanos e computadores” em uma tradução livre. Um Teste de Turing é um teste conceitual na Ciência da Computação para entender se um dado problema é computável, isto é, pode ser resolvido por um computador. Assim, um captcha nada mais é do que um teste de Turing automático para dizer se algo ou alguém é um humano ou um computador.
Existem diversas maneiras de criar captchas e geralmente eles envolvem decifrar enigmas que são muito difíceis para máquinas, geralmente usando imagens e padrões complexos e aleatórios. Certamente você já teve de resolver algum puzzle envolvendo números e letras, ou selecionar as imagens certas em uma lista, mesmo que não soubesse na ocasião o que era um captcha.
No mercado existem diversas soluções de captcha e neste tutorial usaremos uma gratuita fornecida pelo Google, chamada de reCaptcha.
#2 – Setup do Projeto
O Google reCaptcha é uma solução captcha criada e fornecida pelo Google que ajuda tanto os sites deles, quanto os nossos, a se tornarem mais seguros. Confesso que não sei detalhes sobre o algoritmo do teste, mas sei que ele vai muito além do que apenas perguntar sobre “quais imagens são corretas”, analisando aspectos da sessão do usuário no browser como o movimento do mouse e outros, para entender se ele é um bot ou humano. Além disso, certa vez ouvi falar que eles usam as respostas dos usuários para as imagens a fim de ajudar no treinamento das suas IAs. Vai saber.
Para que possamos usar o Google reCaptcha em nosso projeto precisamos primeiro criar uma chave de API, o que você pode fazer neste link.
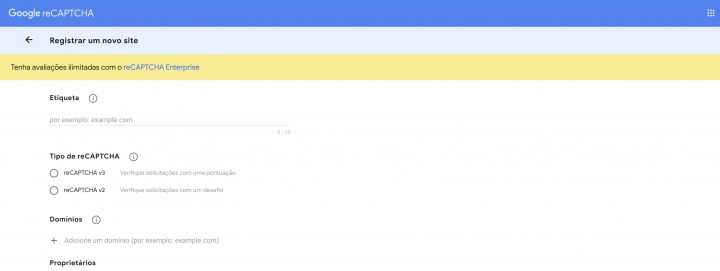
Preencha um nome como etiqueta, escolha a V2 do tipo de reCaptcha (a mais popular) e em domínios você vai colocar os domínios dos sites onde vai usar captcha, não esquecendo de adicionar também localhost para que possamos usar em nossos testes. Aceite os termos de serviço e finalize a criação para, na tela seguinte, poder pegar as suas chaves de API sendo que a que vamos precisar é a “chave de site”.
Para criar o projeto, usaremos um toolkit chamado Vite que vai facilitar a estruturação inicial do projeto. Basta rodar o comando abaixo na pasta onde deseja criar o projeto.
Ele vai pedir o nome do projeto, eu escolhi react-captcha, depois pergunta o framework (React) e a variante (JavaScript). Assim que o projeto terminar de ser criado, entre na pasta do projeto e rode o comando abaixo para instalar a dependência da biblioteca React Google Recaptcha que usaremos neste tutorial. Essa biblioteca exporta um componente React que usaremos na nossa aplicação e que vai simplificar muito a utilização da solução do Google.
Pronto, agora temos todo o ambiente necessário para implementar nosso captcha.
#3 – Implementando o Captcha
Agora crie um arquivo .env na raiz do projeto e coloque nele a seguinte variável de ambiente, com exatamente este mesmo nome e o valor da sua chave de site (sem os < e >).
VITE_SITE_KEY=<sua chave aqui>
Na sequência, vá até o seu src/App.jsx e adicione as importações abaixo no topo do arquivo.
import { useState } from 'react';
import ReCAPTCHA from "react-google-recaptcha";As adições são: useState para gerenciarmos mudança de estado da aplicação e a importação do componente ReCaptcha que usaremos na página.
Agora declare um estado para a situação do captcha e uma função de click que quando disparada irá verificar se o captcha já foi resolvido. Se ainda não foi, a mensagem irá avisar o usuário. Se ele já foi, outra mensagem.
const [captcha, setCaptcha] = useState("");
function onClick() {
if (captcha)
alert('captcha resolvido');
else
alert('captcha pendente');
}Em uma situação real, como em um login por exemplo, pense que quando o captcha foi resolvido você pode fazer a request para o backend processar o login ou o que quer que você queira fazer agora que sabe que o usuário é um ser humano que completou o captcha. Já no caso de cair no else, o entendimento é que o captcha não foi resolvido ou até foi, mas errado.
Para finalizar, vamos ajustar a interface da aplicação de exemplo para incluir o componente de captcha e usar um botão para disparar nossa função de click.
<div style={{ display: 'flex', flexDirection: 'column', alignItems: 'center', justifyContent: 'center', height: '100vh', width: 1200 }}>
<div style={{marginBottom: 10}}>
Test the captcha feature below
</div>
<div style={{marginBottom: 10}}>
<button onClick={onClick}>Click Me</button>
</div>
<div>
<ReCAPTCHA
sitekey={import.meta.env.VITE_SITE_KEY}
onChange={setCaptcha} />
</div>
</div>Repare que o componente ReCaptcha é bem simples de usar, bastando referenciar a sua site key que armazenamos no .env do projeto e a função onChange que será disparada toda vez que o captcha for resolvido.













